bartools: quickstart guide
Dane Vassiliadis, Henrietta Holze
June 27, 2019
bartools_quickstart.RmdBartools Quickstart Guide
0. Install and load the bartools package
You can install bartools from GitHub:
# first install Bioconductor dependencies
if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(c("edgeR", "limma", "ComplexHeatmap"))
# then install bartools via GitHub
if (!requireNamespace("devtools", quietly = TRUE)) {
install.packages("devtools")
}
devtools::install_github("DaneVass/bartools", dependencies = TRUE, force = TRUE)
library(bartools)## Loading required package: edgeR## Loading required package: limma## Loading required package: ggplot2
knitr::opts_chunk$set(dev="png")1. Importing DNA barcode count data
Raw barcode count data can be thought of similarly to raw
integer-based count data from other count based experiments such as
RNA-sequencing. For these data types the edgeR package
provides an efficient DGEList object structure to store
sample counts and associated metadata. bartools makes use
of this object structure to store and process DNA barcode counts.
An example barcoding experiment
For this section we will make use of a hypothetical DNA barcoding dataset based on recent unpublished data from the Dawson lab investigating the response of acute myeloid leukaemia (AML) cells to a novel class of MYST acetyltransferase inhibitor described recently in MacPherson et al. Nature 2019.
AML cells were cultured in vitro, barcoded using a lentiviral based barcoding library called SPLINTR, and transplanted into three groups of C57BL/6J mice with daily dosing of MYST inhibitor at low or high dose or a corresponding vehicle control.
Barcode containing cells were harvested from the bone marrow of diseased mice and sequenced in technical replicate.
To follow along with this vignette the raw counts tables and sample
metadata are included in the bartools package.
data(test.dge)Generating a DGEList object from sample counts and metadata
Counts objects defined above can be specified in a sample metadata
sheet as shown below. This is the easiest way to generate a
DGEList object containing the count information and
metadata of interest for a set of barcode sequencing samples. An example
of this process is shown below.
samplesheet <- read.csv(
system.file(
"extdata",
"test_sampletable.csv",
package = "bartools",
mustWork = T
),
header = T,
stringsAsFactors = F
)
samplesheetTo read in a sample sheet in excel format:
samplesheet <-
readxl::read_excel(
"samplesheet.xlsx"
)
samplesheet <- as.data.frame(samplesheet)
rownames(samplesheet) <- samplesheet$sample
samplesheetWhatever format your sample sheet is in, make sure that the rownames are your unique sample names.
Load in the counts as specified in the samplesheet into a DGEList object. The function expects file locations to be specified either as character vector of filenames, or as a column named files in the samplesheet.
dge <- edgeR::readDGE(
files = samplesheet,
group = samplesheet$treatment,
labels = samplesheet$sample,
header = F
)This results in the creation of a DGEList object containing counts and metadata information for each sample.
# Load the test dataset
data(test.dge)
test.dge## An object of class "DGEList"
## $samples
## Sample Experiment Group PCR_Replicate Treatment group
## T0-1 T0-1 test_01 T0 1 T0 T0
## T0-2 T0-2 test_01 T0 2 T0 T0
## S10-1 S10-1 test_01 10_High_dose 1 High_dose 10_High_dose
## S10-2 S10-2 test_01 10_High_dose 2 High_dose 10_High_dose
## S11-1 S11-1 test_01 11_Vehicle 1 Vehicle 11_Vehicle
## lib.size norm.factors
## T0-1 3584606 1
## T0-2 3349340 1
## S10-1 4114186 1
## S10-2 4196458 1
## S11-1 2907500 1
## 33 more rows ...
##
## $counts
## Samples
## Tags T0-1 T0-2 S10-1 S10-2 S11-1 S11-2 S12-1 S12-2 S13-1 S13-2 S14-1 S14-2
## BC_1 175 79 0 0 0 0 0 0 0 0 0 0
## BC_13 1458 834 0 0 0 0 0 0 0 0 0 0
## BC_99 1155 1554 0 0 0 0 0 0 0 0 0 0
## BC_120 285 184 0 0 0 0 0 0 0 0 0 0
## BC_351 0 0 0 0 0 0 0 0 0 0 0 0
## Samples
## Tags S15-1 S15-2 S16-1 S16-2 S17-1 S17-2 S18-1 S18-2 S1-1 S1-2 S2-1 S2-2
## BC_1 0 0 0 0 0 0 0 0 0 0 0 0
## BC_13 0 0 0 0 0 0 0 0 0 0 0 0
## BC_99 0 0 0 0 0 0 0 0 105 205 0 0
## BC_120 0 0 0 0 0 0 0 0 0 0 0 0
## BC_351 0 0 0 0 0 0 0 0 0 0 0 0
## Samples
## Tags S3-1 S3-2 S4-1 S4-2 S5-1 S5-2 S6-1 S6-2 S7-1 S7-2 S8-1 S8-2 S9-1 S9-2
## BC_1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## BC_13 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## BC_99 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## BC_120 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## BC_351 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 1634 more rows ...2. Data QC and Normalisation
Data QC
We first want to ensure that we are working with clean data. Using
the thresholdCounts() function we can determine an
appropriate threshold to apply to the data to maximise signal to noise
and retain true and informative barcodes.
We can test different thresholding parameters, such as absolute thresholds on total read counts as below.
# Remove barcodes (rows) with no data
test.dge <- test.dge[rowSums(test.dge$counts) != 0, ]
thresholdCounts(
test.dge,
type = "absolute",
threshold = 1,
minSamples = 1,
plot = T,
group = "Treatment"
)## DGEList dimensions pre-threshold## [1] 1490 38## DGEList dimensions post-threshold## [1] 1490 38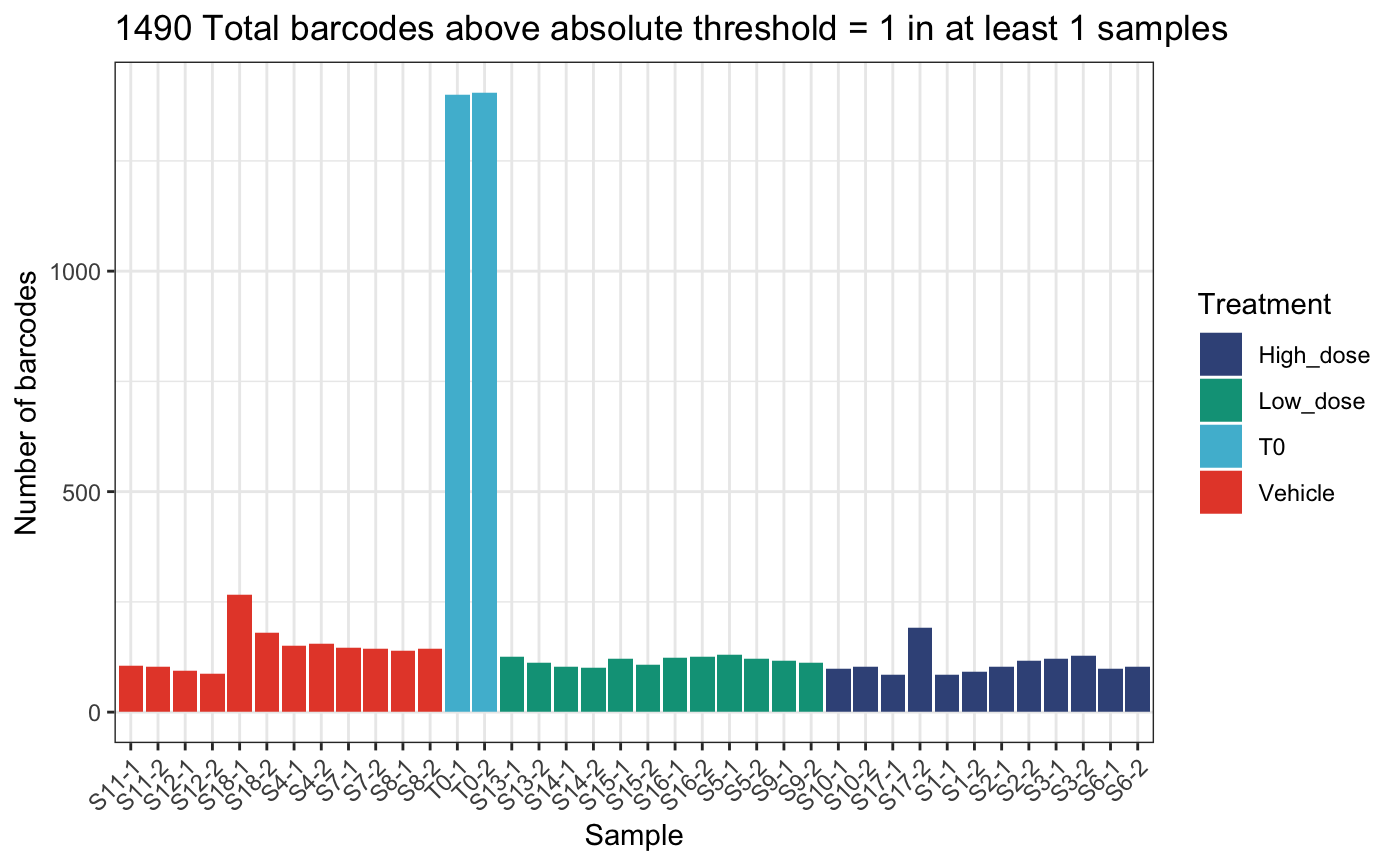
thresholdCounts(
test.dge,
type = "absolute",
threshold = 10,
minSamples = 1,
plot = T,
group = "Treatment"
)## DGEList dimensions pre-threshold## [1] 1490 38## DGEList dimensions post-threshold## [1] 1462 38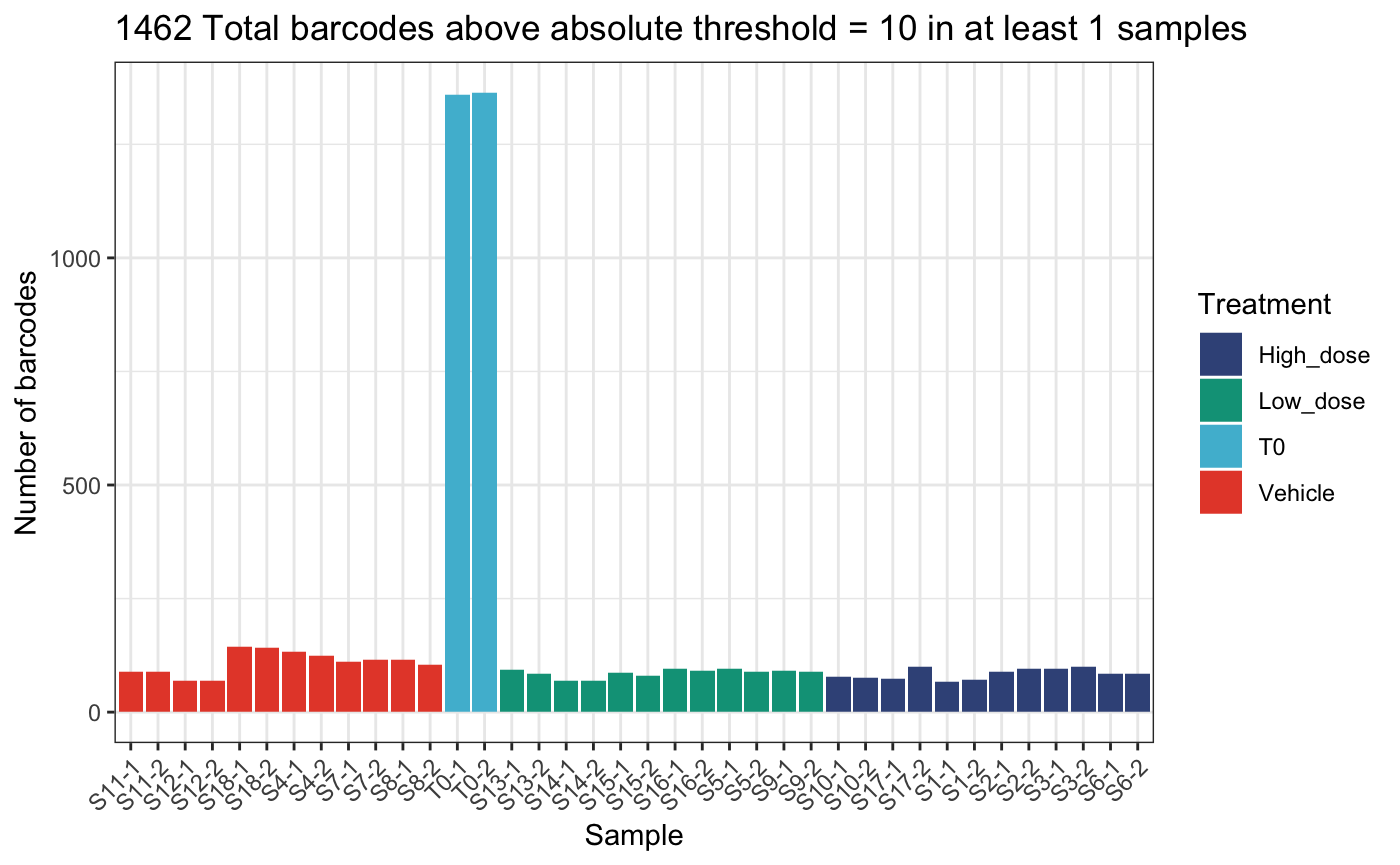
thresholdCounts(
test.dge,
type = "absolute",
threshold = 10,
minSamples = 3,
plot = T,
group = "Treatment"
)## DGEList dimensions pre-threshold## [1] 1490 38## DGEList dimensions post-threshold## [1] 387 38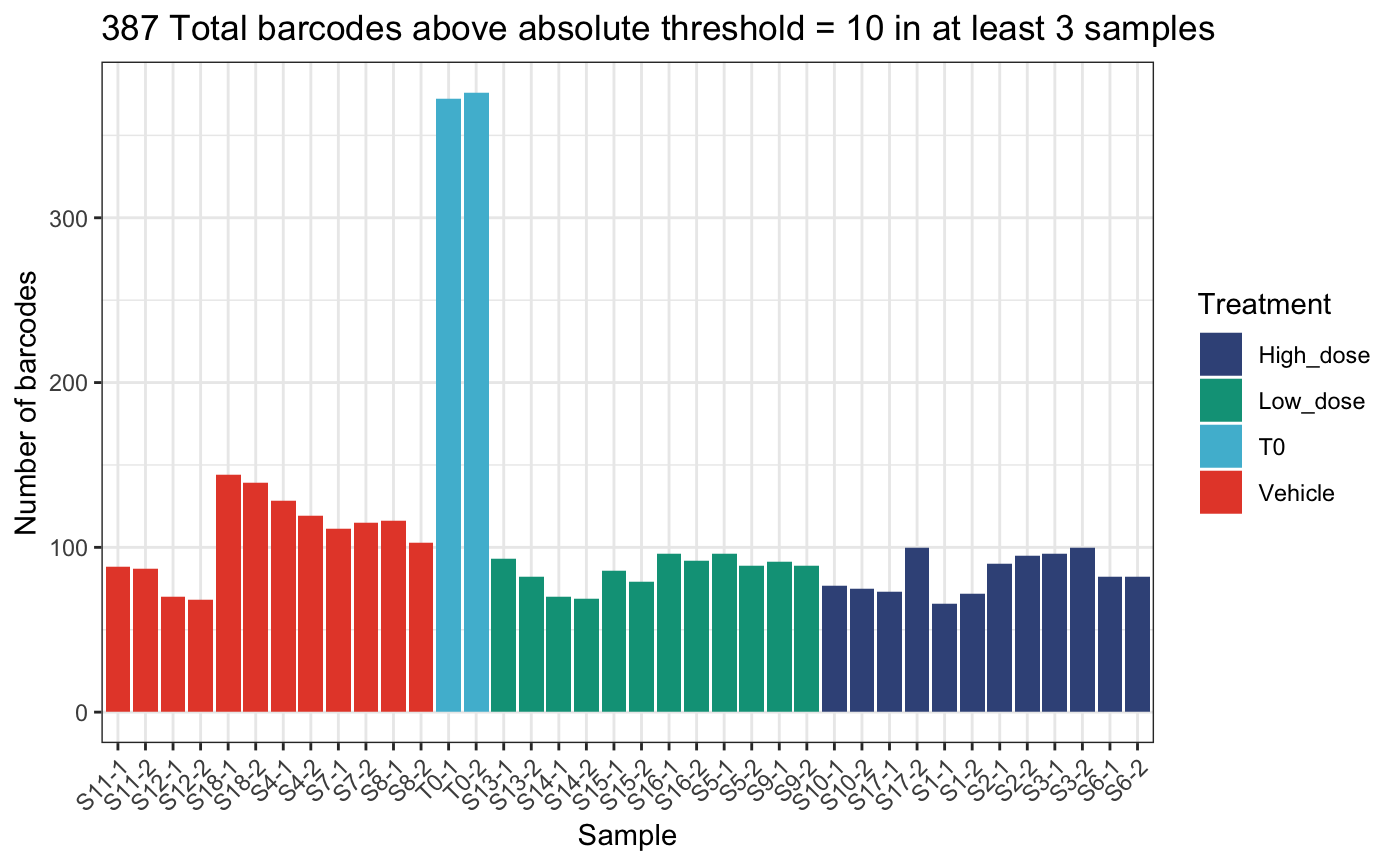
Or relative thresholds based on proportion within a sample.
thresholdCounts(
test.dge,
type = "relative",
threshold = 1e-10,
minSamples = 1,
plot = T,
group = "Treatment"
)## DGEList dimensions pre-threshold## [1] 1490 38## DGEList dimensions post-threshold## [1] 1490 38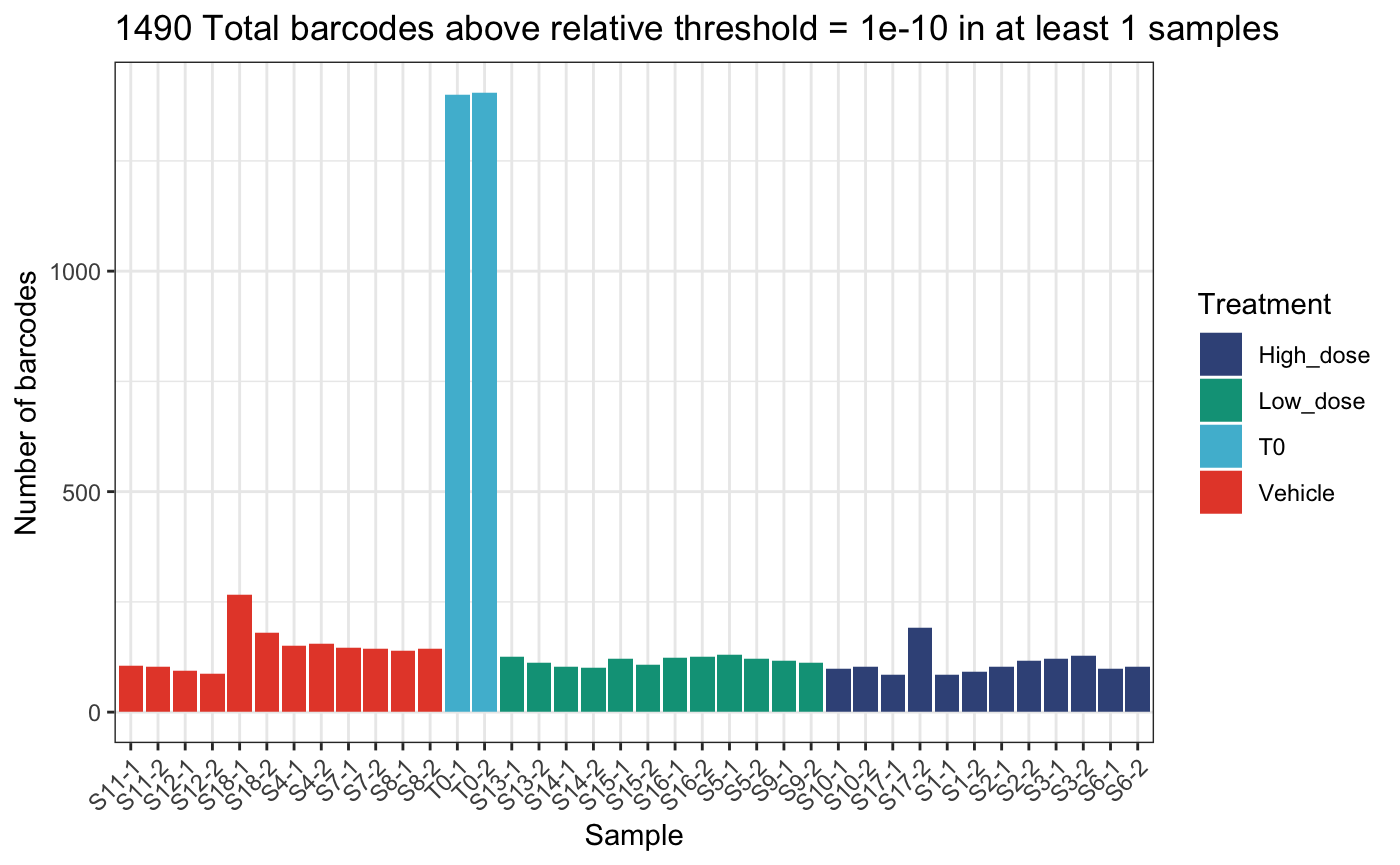
thresholdCounts(
test.dge,
type = "relative",
threshold = 1e-5,
minSamples = 1,
plot = T,
group = "Treatment"
)## DGEList dimensions pre-threshold## [1] 1490 38## DGEList dimensions post-threshold## [1] 1381 38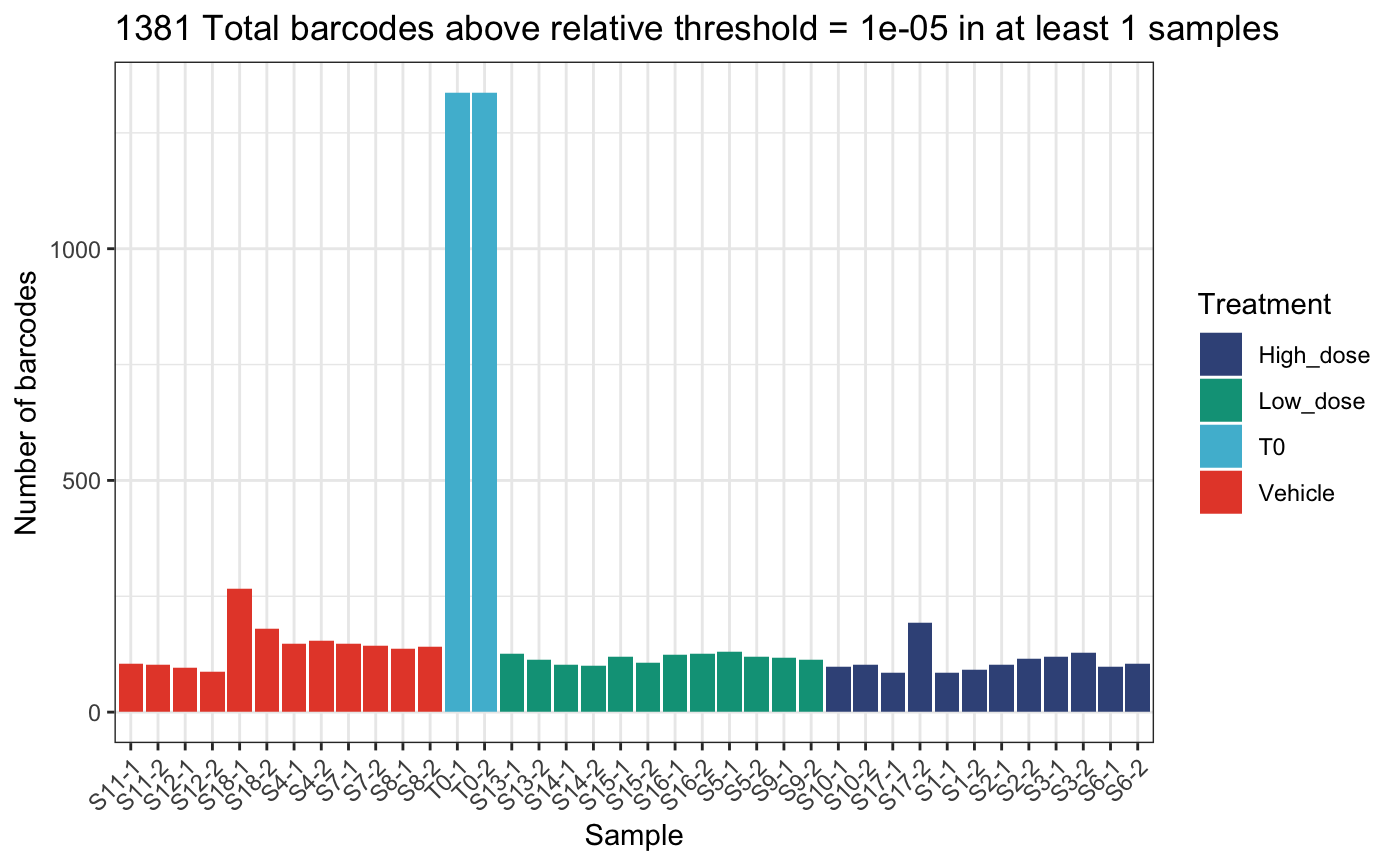
thresholdCounts(
test.dge,
type = "relative",
threshold = 1e-5,
minSamples = 3,
plot = T,
group = "Treatment"
)## DGEList dimensions pre-threshold## [1] 1490 38## DGEList dimensions post-threshold## [1] 322 38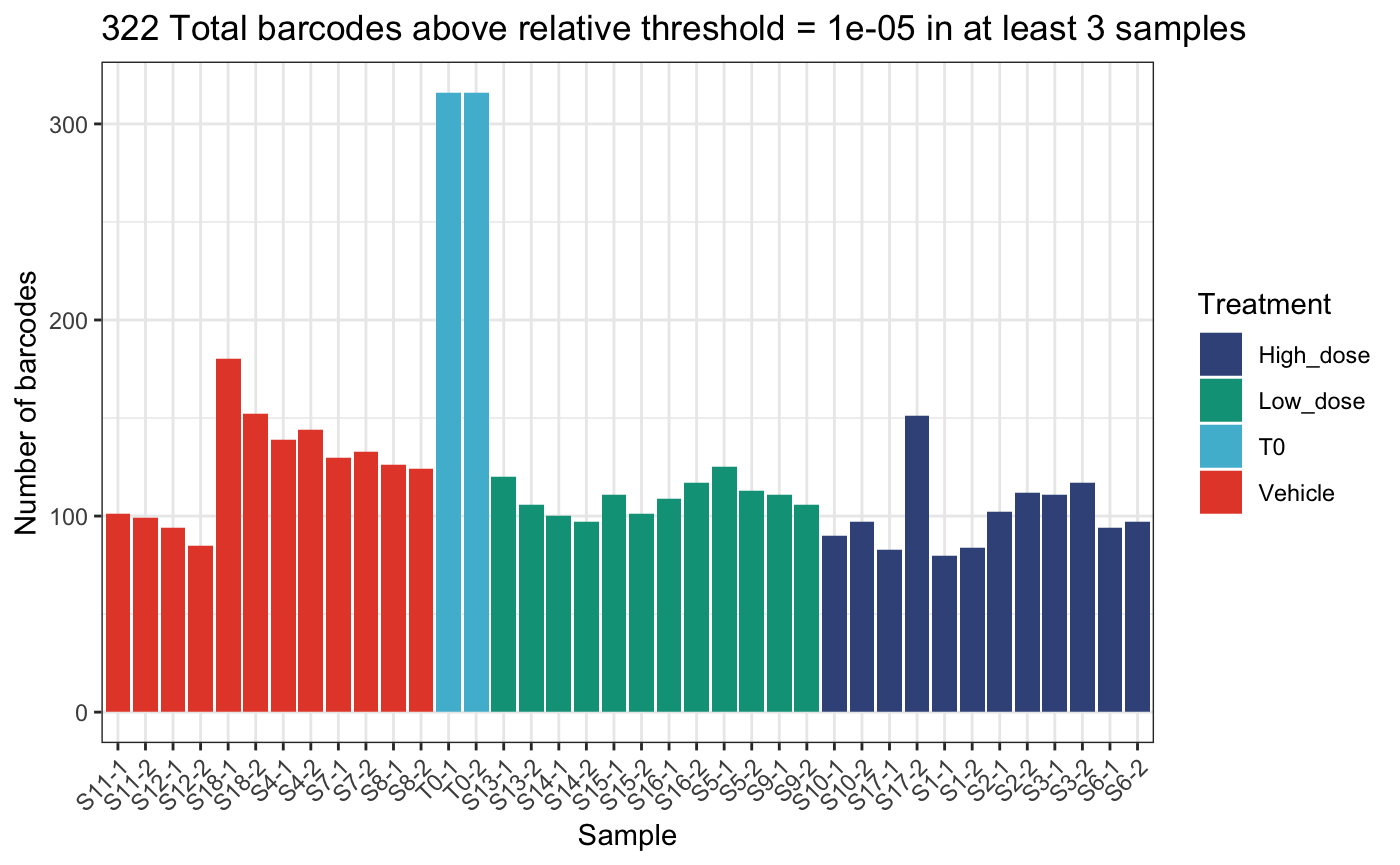
Here we will continue with an absolute threshold of 10.
dge.filtered <-
thresholdCounts(
test.dge,
type = "absolute",
threshold = 10,
minSamples = 2,
plot = F
)## DGEList dimensions pre-threshold## [1] 1490 38## DGEList dimensions post-threshold## [1] 1316 38We then normalise samples to sequencing depth to counts per million
using normaliseCounts().
dge.cpmnorm <- normaliseCounts(dge.filtered, method = "CPM")We can plot the raw and normalised sequencing depth to get an idea of depth discrepancies between PCR replicates.
# raw counts per sample
plotReadCounts(dge.filtered, group = "Treatment")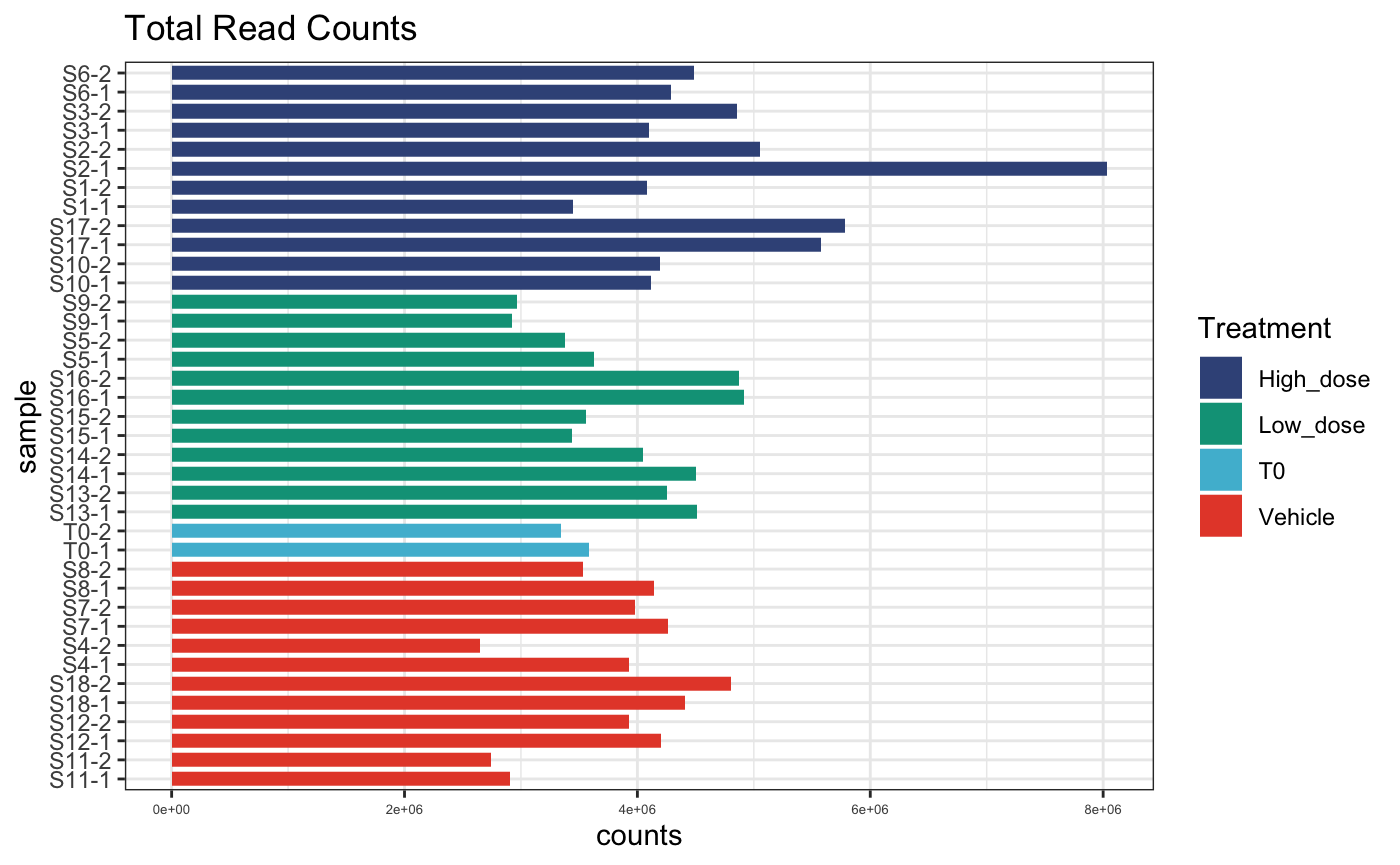
# normalised counts per sample
plotReadCounts(dge.cpmnorm, group = "Treatment")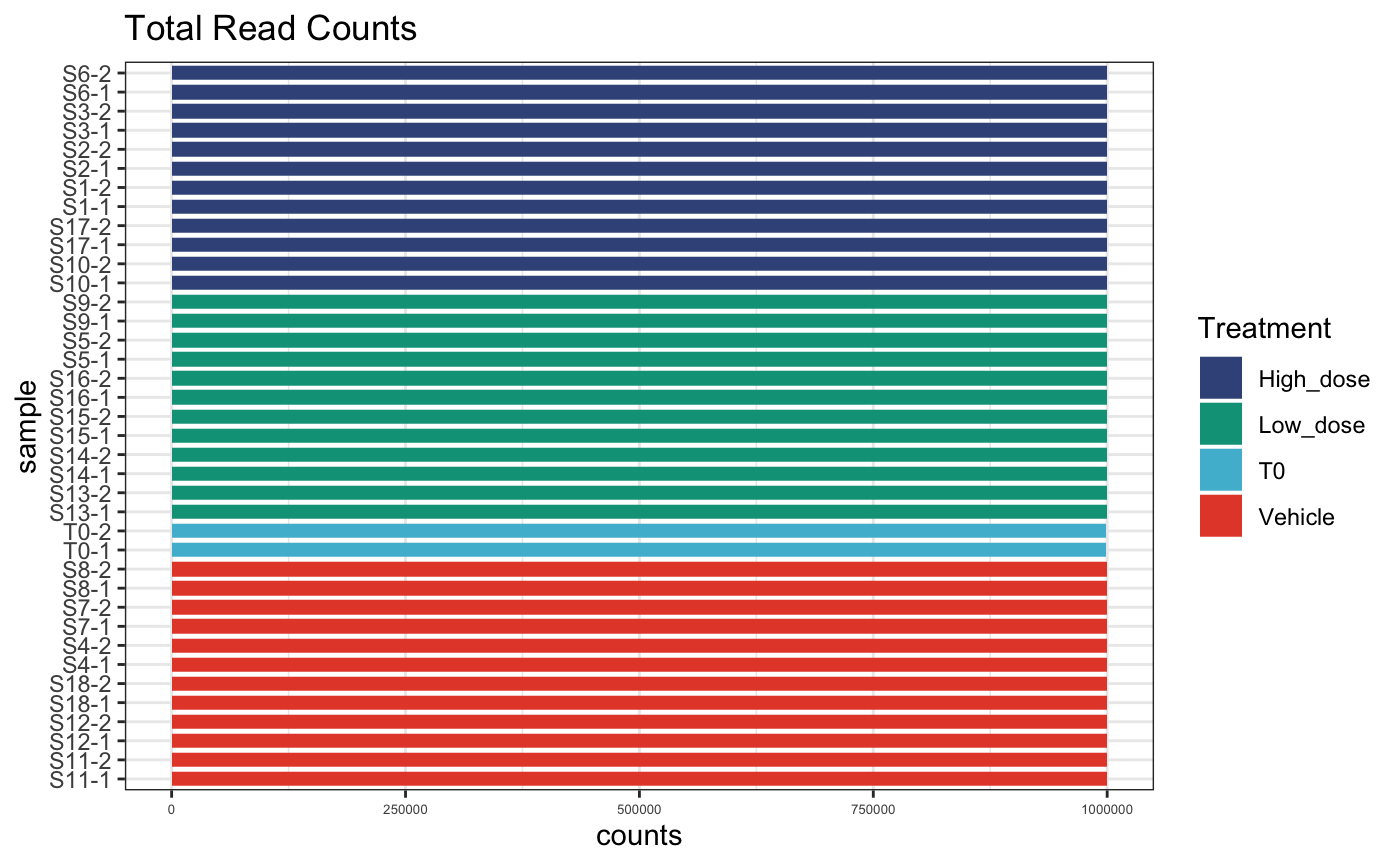
For lentiviral based cellular barcoding experiments, such as this
one, it is common for the library to exhibit a degree of skewness based
on the cloning method. This means that some barcodes are represented in
the library more than others and so have a greater chance to be
transduced into multiple cells.
Most experiments assume that each individual barcode is transduced into only one cell, and that each cell is only transduced with one barcode. This is ensured using a low multiplicity of infection (MOI) transduction in which the likelihood that a cell is transduced with one or more barcode containing virions follows a Poisson distribution.
With this in mind, it also can be useful to check the total counts
per barcode to identify bias in counts in sample vs. frequency of
barcode in reference library.
The barcodes are labelled based on their ranked frequency in the
reference library.
# plot detected barcodes ordered by frequency in reference library
plotBarcodeCounts(dge.cpmnorm, log10 = F)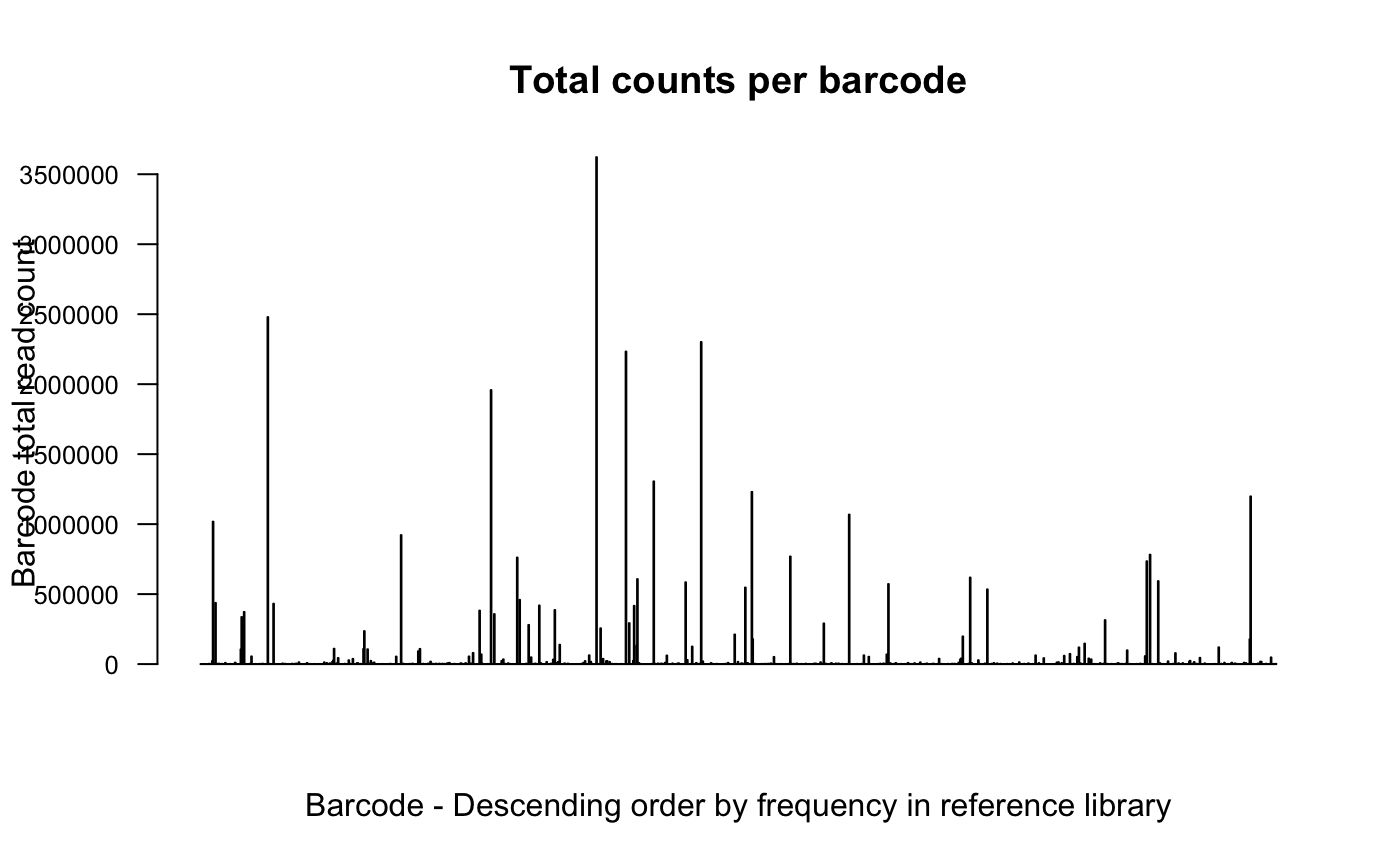
# plot log10 barcode counts
plotBarcodeCounts(dge.cpmnorm, log10 = T)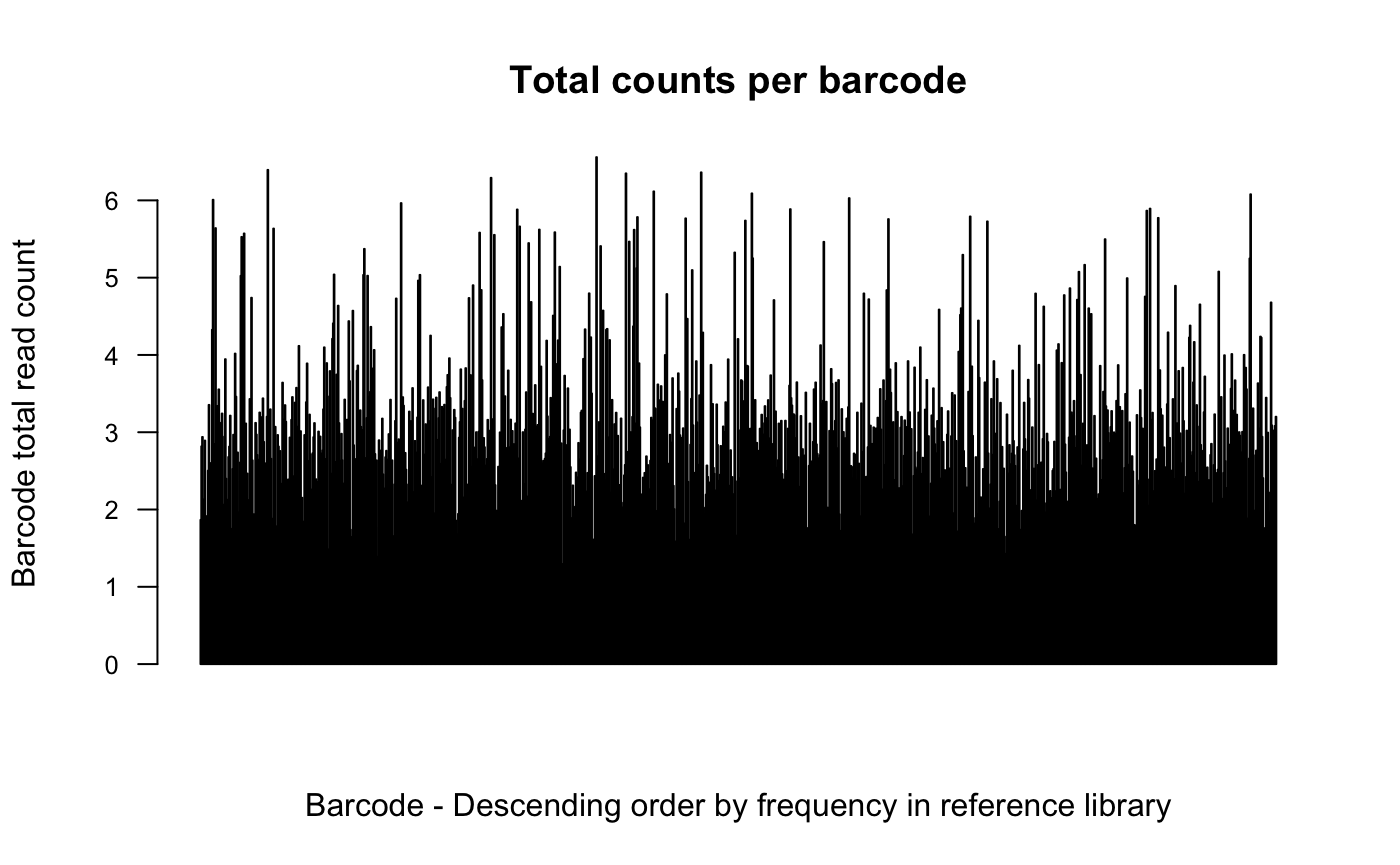
# order barcodes by count across samples
plotBarcodeCounts(dge.cpmnorm, log10 = F, order = T)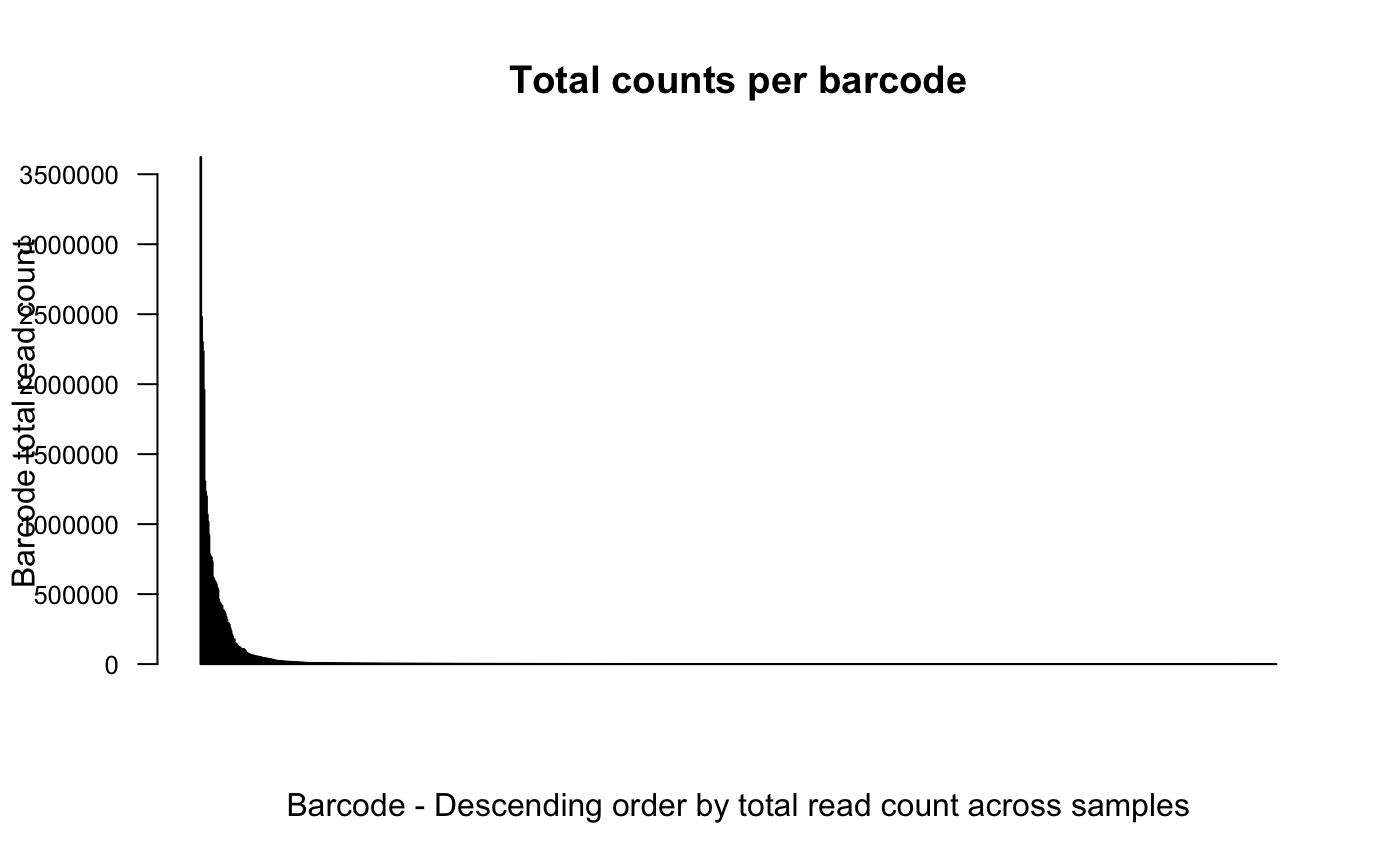
# order barcodes by count across samples with log norm
plotBarcodeCounts(dge.cpmnorm, log10 = T, order = T)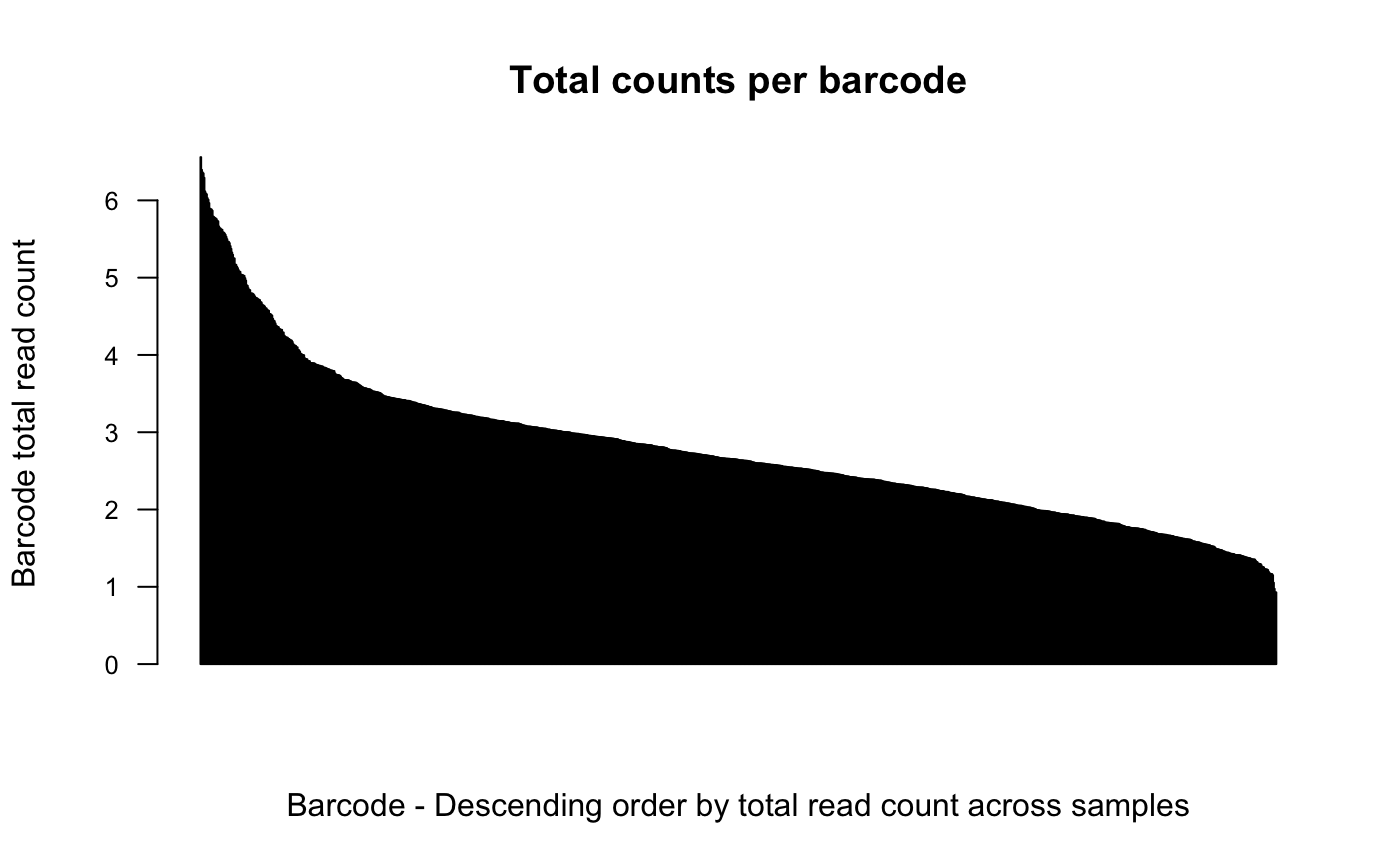
In the first and second plot individual barcodes on the x-axis are
ordered based on their frequency in the reference library pool.
An increased number of counts per barcode toward the left hand side of
the plot would be suggestive of transduction bias, meaning that there
are more reads on average attributed to the more abundant barcodes in
the library. And so, likely multiple cells were transduced with the same
barcode.
We don’t see this here suggesting that this is not a problem for this
experiment.
Check correlation between PCR replicates
It is also important to ensure that individual samples are sequenced to an appropriate depth as this ensures that the entire barcode repertoire present in a sample is captured in the data. Sequencing technical duplicates of a sample generated at the library PCR stage is a good way to ensure this.
In our experiment we have 9 samples total, each with two PCR
technical replicates. Here, we correlate the barcode distributions for
each pair of technical replicates.
NB: This only works for paired replicates, i.e. not more than 2.
# get all unique samples
# column "group" contains information on replicates here
unique_samples <- unique(dge.filtered$samples$group)
# only plot subset of samples.
lapply(unique_samples[1], function(x) {
# subset dge object to get replicates of sample
replicate_names <- colnames(dge.filtered)[dge.filtered$samples$group %in% as.character(x)]
plotBarcodeRegression(
dge.filtered,
sample1 = replicate_names[1],
sample2 = replicate_names[2],
rug = T,
trans = "log1p"
)
})## [[1]]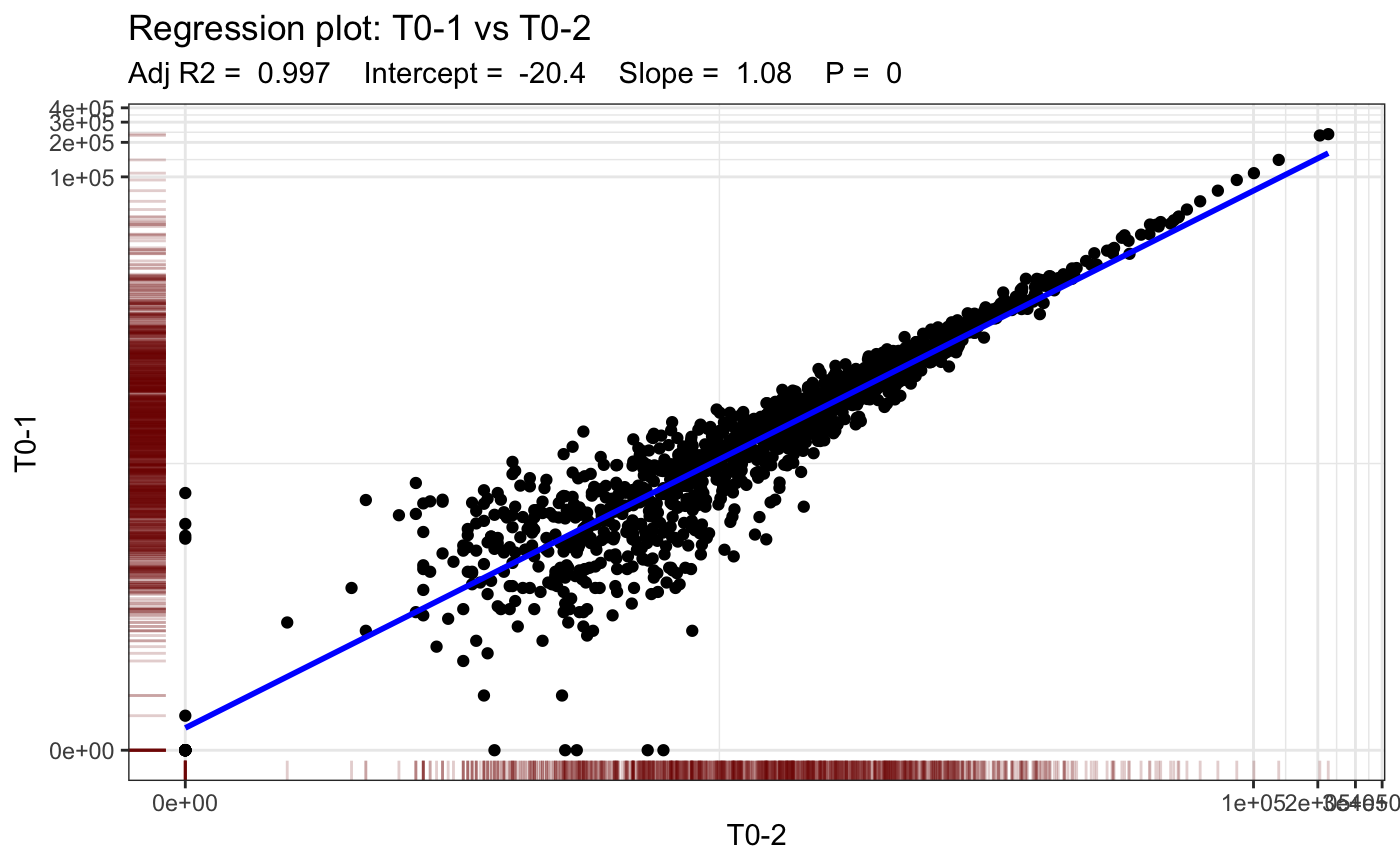
We fit a linear model to both technical replicates per sample and plot the regression line. Note that we expect a very high correlation because these are PCR replicates of the same barcode pool.
We can also easily get the correlation values between replicates
using calcReplicateCorr.
Samples can be filtered for high or low correlation using the
threshold and return variables.
corrs <- calcReplicateCorr(dge.filtered, group = "Group")
corrs[which(corrs < 0.999)]## 11_Vehicle 2_High_dose 4_Vehicle T0
## 0.9988324 0.9975019 0.9975590 0.9983700
corrs## 1_High_dose 10_High_dose 11_Vehicle 12_Vehicle 13_Low_dose 14_Low_dose
## 0.9990488 0.9998575 0.9988324 0.9992809 0.9999569 0.9999779
## 15_Low_dose 16_Low_dose 17_High_dose 18_Vehicle 2_High_dose 3_High_dose
## 0.9998939 0.9998964 0.9998268 0.9995622 0.9975019 0.9997354
## 4_Vehicle 5_Low_dose 6_High_dose 7_Vehicle 8_Vehicle 9_Low_dose
## 0.9975590 0.9999389 0.9994985 0.9997087 0.9992878 0.9997056
## T0
## 0.9983700Finally sample replicates can be correlated globally using
plotBarcodeCorrelation.
# Pearson correlation, full
plotBarcodeCorrelation(dge.filtered, clustered = T, upper = F, method = "pearson")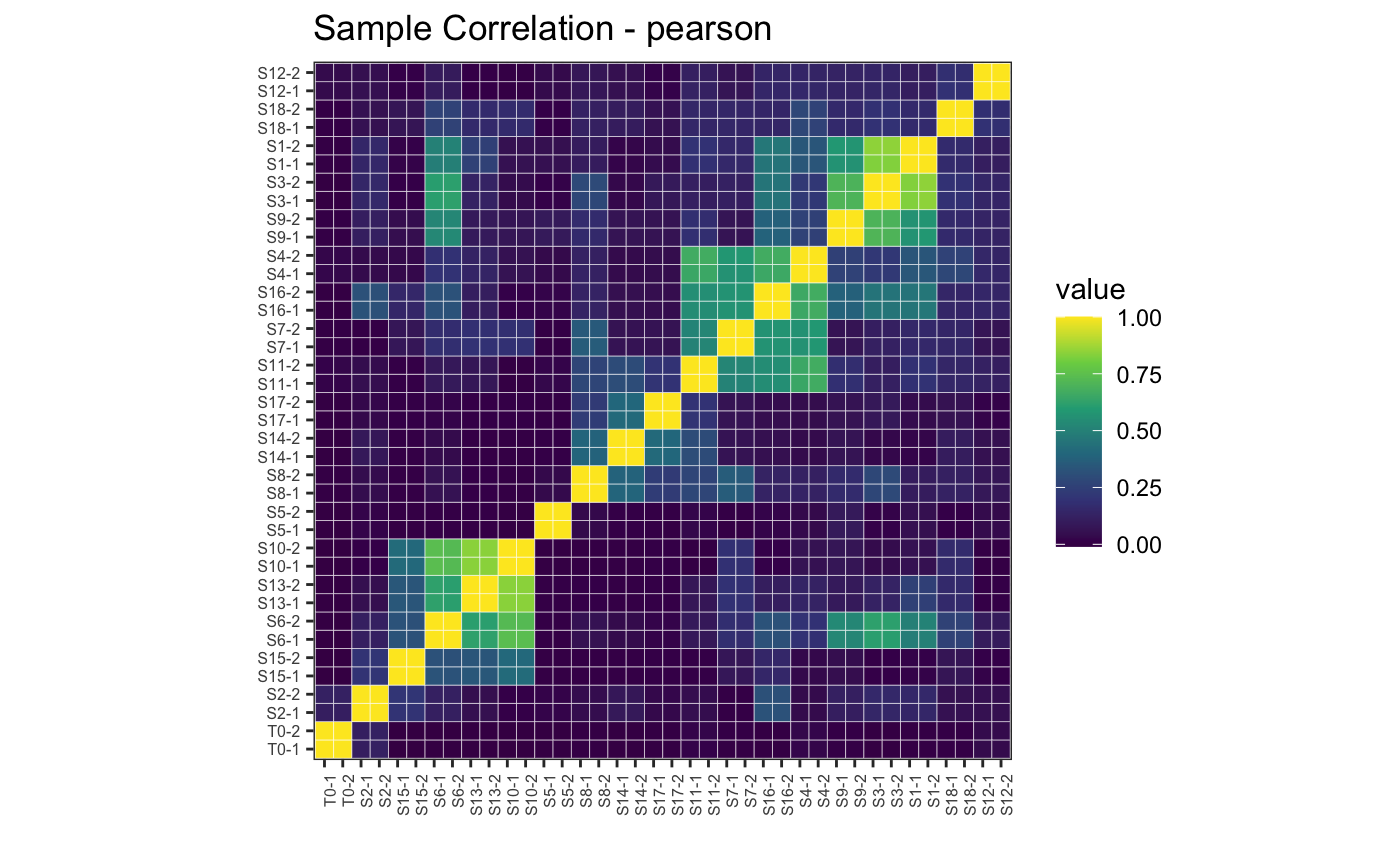
# Pearson correlation, upper
plotBarcodeCorrelation(dge.filtered, clustered = T, upper = T, method = "pearson")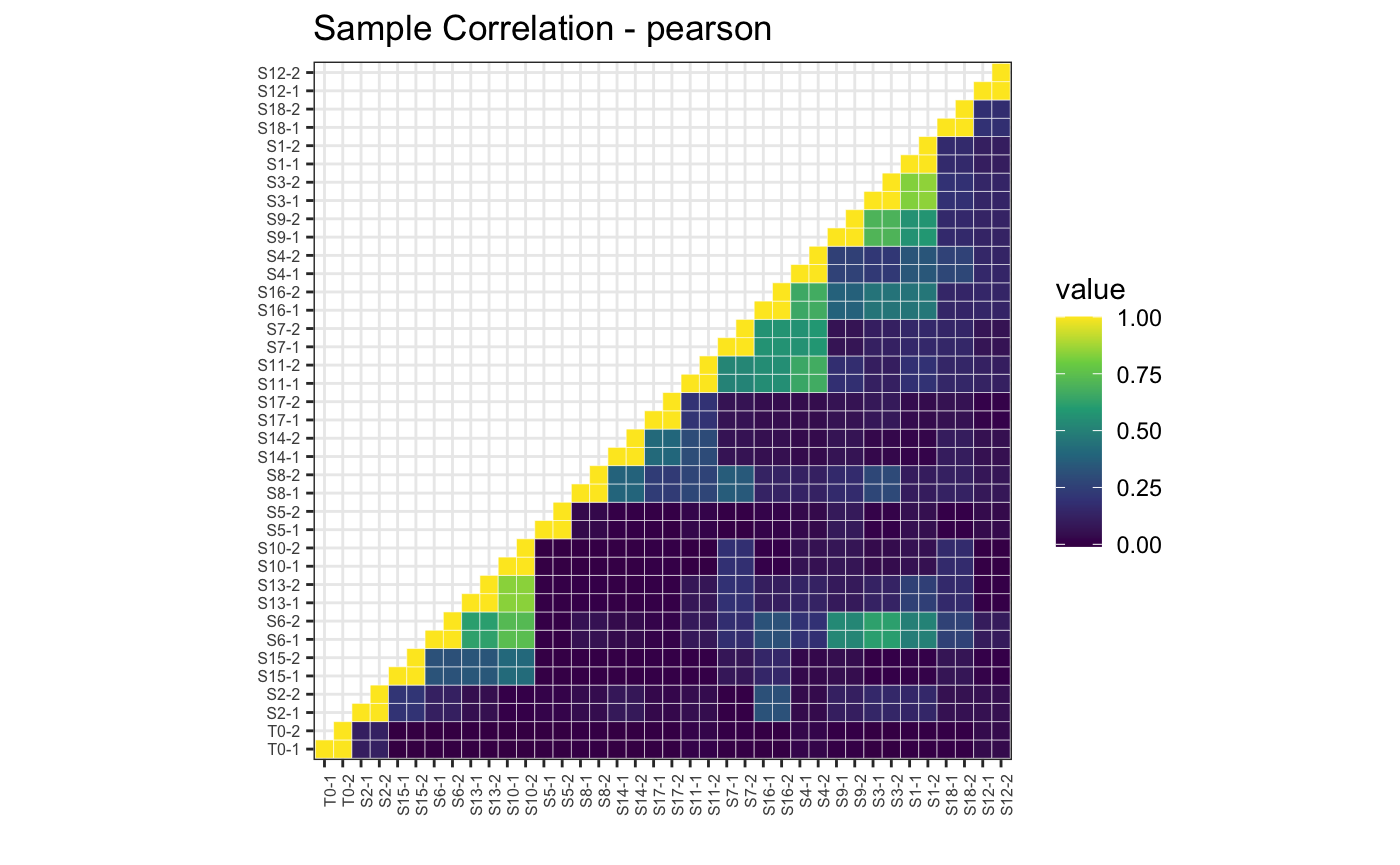
# Spearman correlation
plotBarcodeCorrelation(dge.filtered, clustered = T, upper = T, method = "spearman")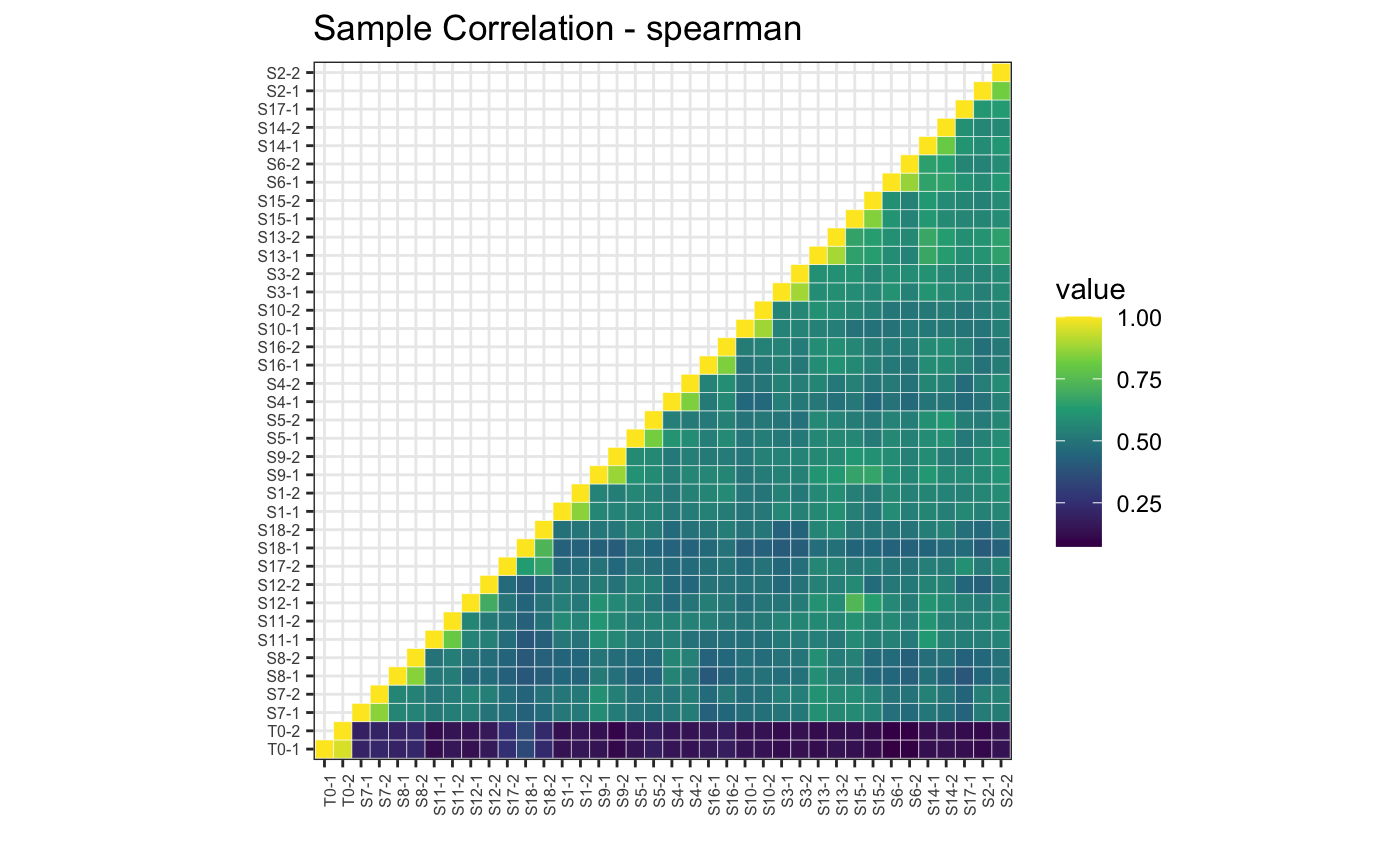
Collapse PCR replicates in object
Now that we know our samples are of good quality we have no further use of the PCR replicate information. From this point onward its a good idea to collapse our PCR replicates.
dim(dge.filtered)## [1] 1316 38collapseReplicates can take the average (default
behavior) or the sum of PCR technical replicates within each sample.
Here we take the average. Users may want to sum PCR replicates if there
is evidence of sampling bias across technical repeats (i.e. poor
correlation score or other evidence).
dge.filtered.collapsed <- collapseReplicates(
dge.filtered,
group = "group",
method = "mean"
)The result is a clean barcode sequencing dataset ready for further investigation and visualisation.
head(dge.filtered.collapsed)## An object of class "DGEList"
## $samples
## Sample Experiment Group PCR_Replicate Treatment
## 1_High_dose S1-1 test_01 1_High_dose 1 High_dose
## 10_High_dose S10-1 test_01 10_High_dose 1 High_dose
## 11_Vehicle S11-1 test_01 11_Vehicle 1 Vehicle
## 12_Vehicle S12-1 test_01 12_Vehicle 1 Vehicle
## 13_Low_dose S13-1 test_01 13_Low_dose 1 Low_dose
## group lib.size norm.factors Sample BC.count
## 1_High_dose 1_High_dose 3447629 1 S1-1 66
## 10_High_dose 10_High_dose 4114186 1 S10-1 78
## 11_Vehicle 11_Vehicle 2907500 1 S11-1 88
## 12_Vehicle 12_Vehicle 4202337 1 S12-1 70
## 13_Low_dose 13_Low_dose 4513559 1 S13-1 93
## 14 more rows ...
##
## $counts
## Samples
## Tags 1_High_dose 10_High_dose 11_Vehicle 12_Vehicle 13_Low_dose 14_Low_dose
## BC_1 0 0 0 0 0 0
## BC_13 0 0 0 0 0 0
## BC_99 155 0 0 0 0 0
## BC_120 0 0 0 0 0 0
## BC_426 0 0 0 0 0 0
## BC_430 0 0 0 0 0 0
## Samples
## Tags 15_Low_dose 16_Low_dose 17_High_dose 18_Vehicle 2_High_dose
## BC_1 0 0 0.0 0.0 0
## BC_13 0 0 0.0 0.0 0
## BC_99 0 0 0.0 0.0 0
## BC_120 0 0 0.0 0.0 0
## BC_426 0 0 0.0 0.0 0
## BC_430 0 0 0.5 413.5 0
## Samples
## Tags 3_High_dose 4_Vehicle 5_Low_dose 6_High_dose 7_Vehicle 8_Vehicle
## BC_1 0 0.0 0 0 0.0 0
## BC_13 0 0.0 0 0 0.0 0
## BC_99 0 0.0 0 0 0.0 0
## BC_120 0 0.0 0 0 0.0 0
## BC_426 0 0.0 0 0 0.0 0
## BC_430 0 13.5 0 0 0.5 0
## Samples
## Tags 9_Low_dose T0
## BC_1 0 127.0
## BC_13 0 1146.0
## BC_99 0 1354.5
## BC_120 0 234.5
## BC_426 0 81.0
## BC_430 0 1022.0If we repeat the above correlation plots we can see general similarities across samples
# Pearson correlation, full
plotBarcodeCorrelation(dge.filtered.collapsed, clustered = T, upper = F, method = "pearson")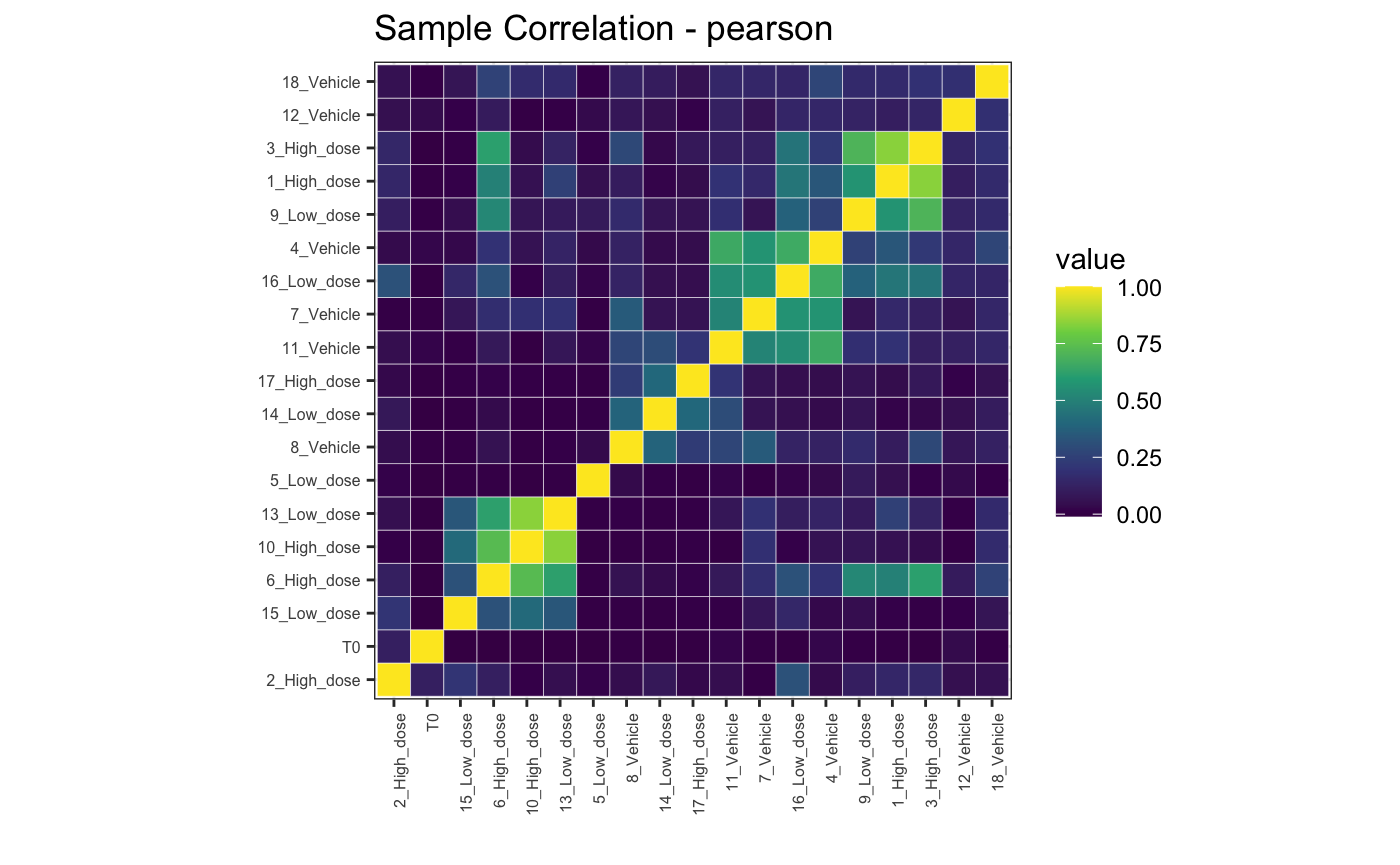
3. Visualisation
bartools includes a range of visualisation options for
examining barcode-seq datasets.
Bubble plot
Sometimes a visual depiction of the data is most suitable. Here, barcodes/tags are represented by bubbles aligned on a single plane. The size of the bubbles reflects the percentage abundance of each barcode within a sample.
plotBarcodeBubble(dge.filtered.collapsed,
proportionCutoff = 10,
labelBarcodes = T)## Warning: Vectorized input to `element_text()` is not officially supported.
## ℹ Results may be unexpected or may change in future versions of ggplot2.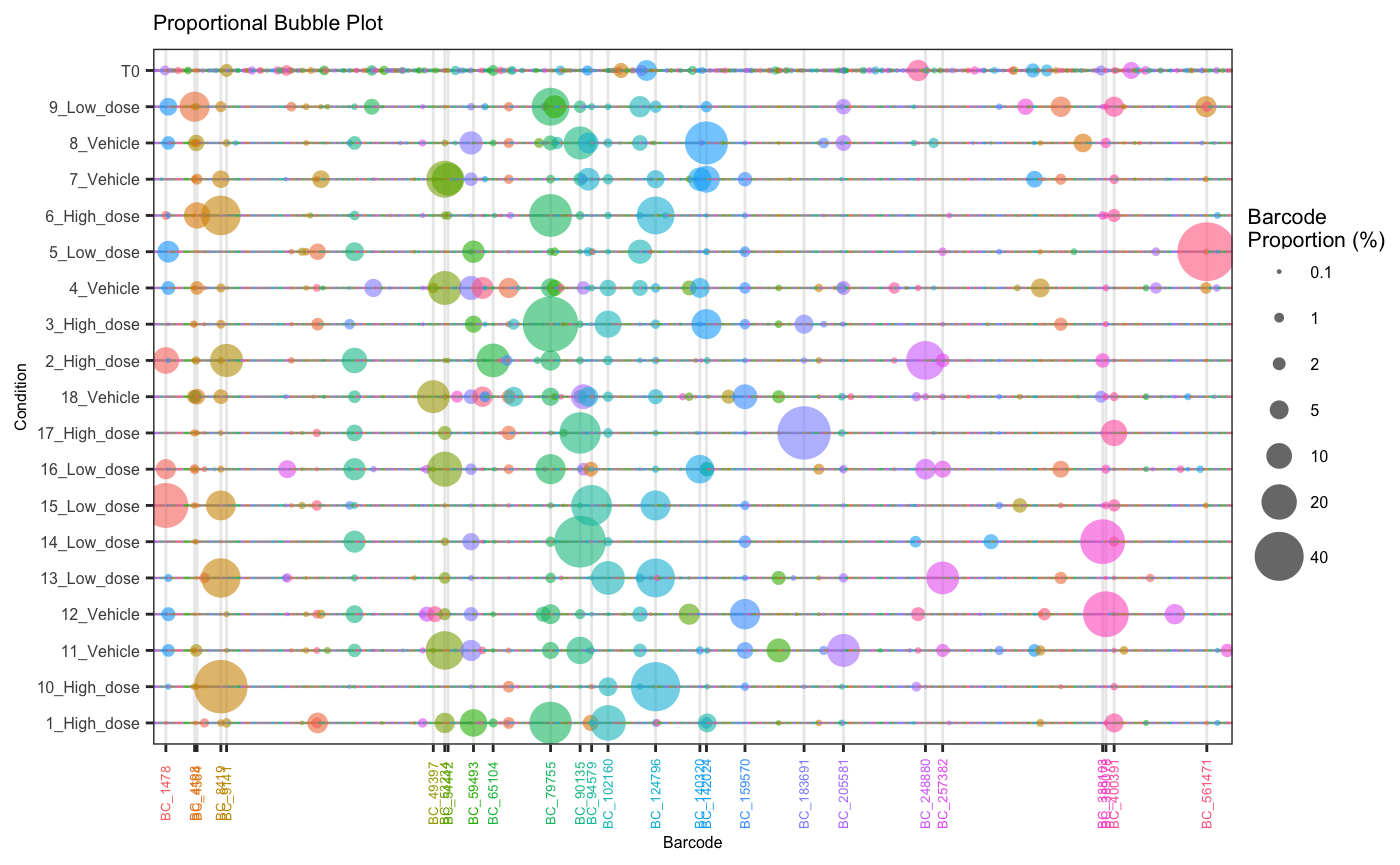
Using the orderSample parameter, bubbleplots can also be
arranged according to frequency in a particular sample which can help
with visual comparison of large vs small clones across samples and
conditions.
plotOrderedBubble(dge.filtered.collapsed,
proportionCutoff = 10,
labelBarcodes = T,
orderSample = "T0",
colorDominant = F,
filterCutoff = 0.001,
group = "Treatment")## Warning: Vectorized input to `element_text()` is not officially supported.
## ℹ Results may be unexpected or may change in future versions of ggplot2.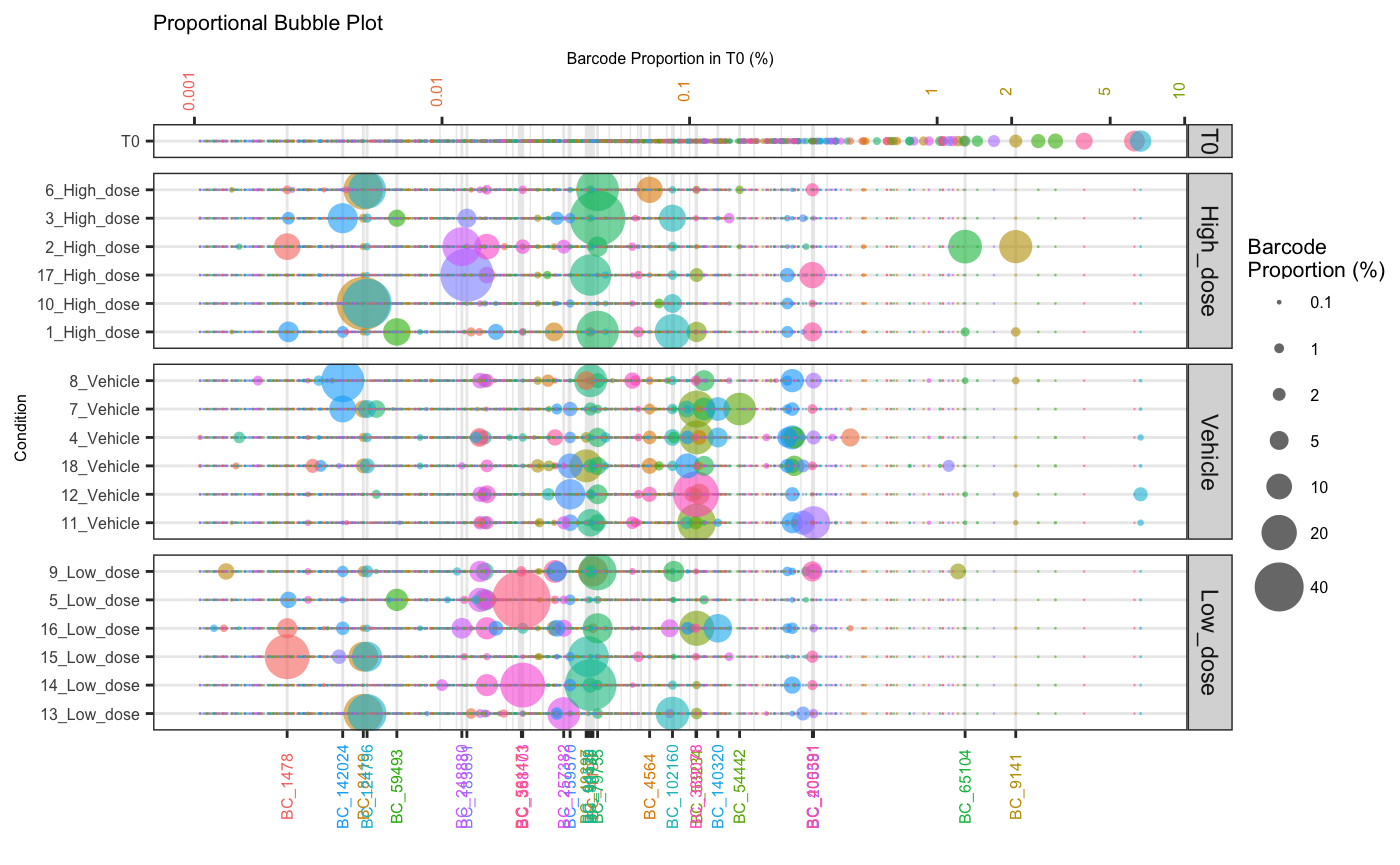
Barcodes that fail to meet a defined abundance threshold in any sample can be greyed out.
plotOrderedBubble(dge.filtered.collapsed,
proportionCutoff = 10,
labelBarcodes = T,
orderSample = "T0",
colorDominant = T,
filterCutoff = 0.001,
group = "Treatment")## Warning: Vectorized input to `element_text()` is not officially supported.
## ℹ Results may be unexpected or may change in future versions of ggplot2.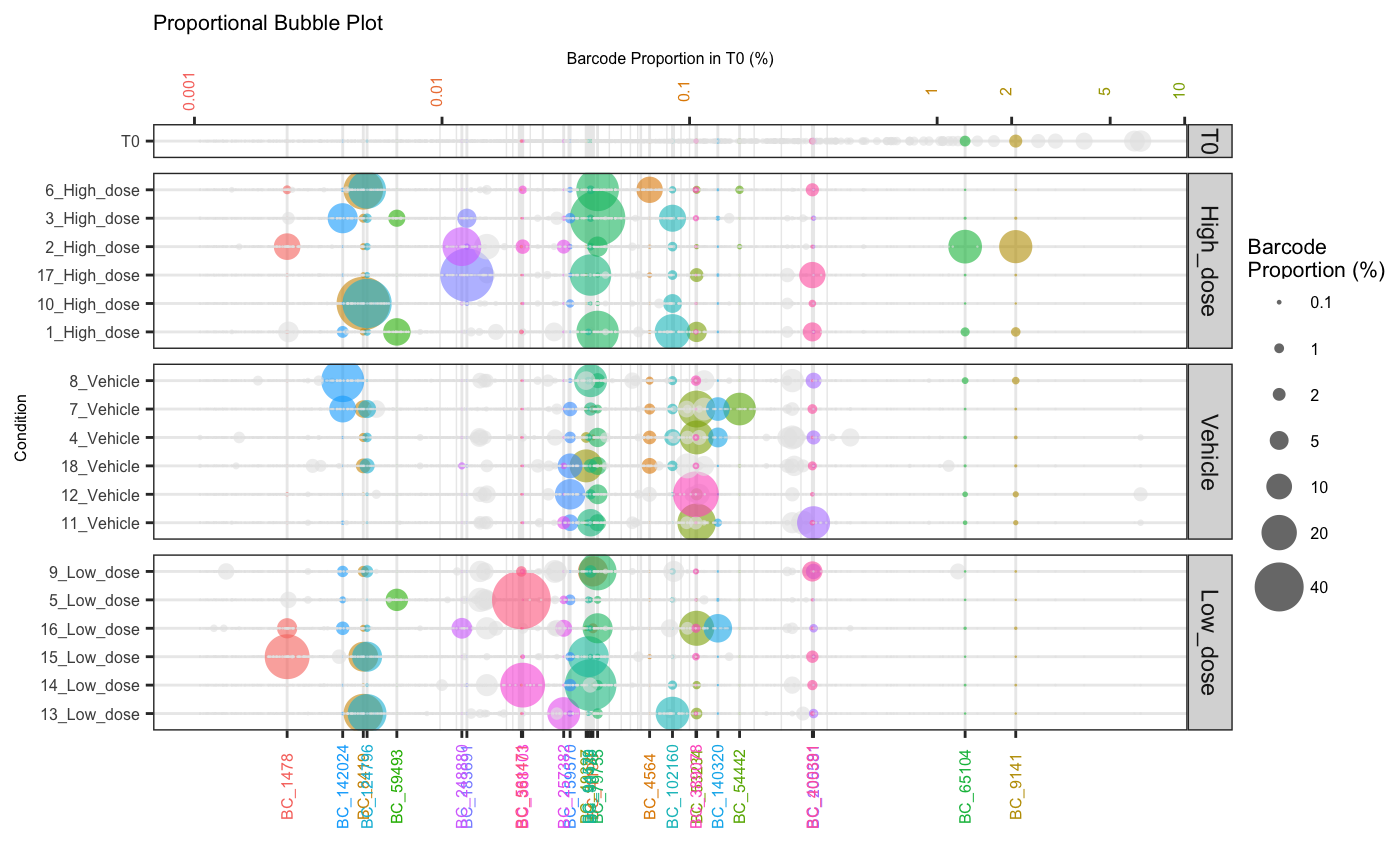
Or filtered from the plot entirely using filterCutoff
parameters
plotOrderedBubble(dge.filtered.collapsed,
proportionCutoff = 10,
labelBarcodes = T,
orderSample = "T0",
colorDominant = T,
filterCutoff = 0.1,
group = "Treatment")## Warning: Vectorized input to `element_text()` is not officially supported.
## ℹ Results may be unexpected or may change in future versions of ggplot2.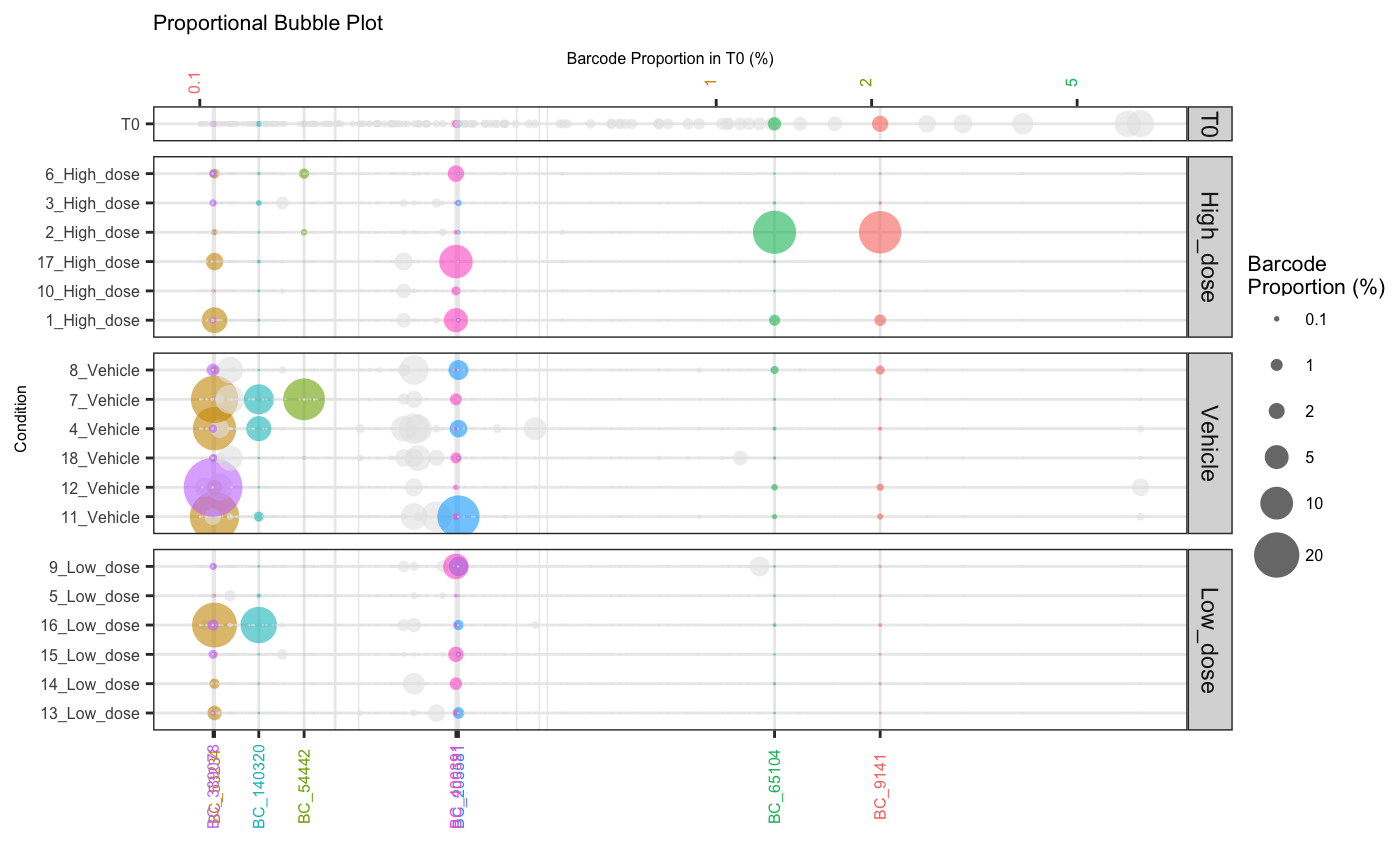
Barcode Plot
Alternatively, we can focus in on the most abundant barcodes within a set of samples to more easily observe how these change in frequency over the course of an experiment.
plotBarcodeHistogram(dge.filtered.collapsed, topN = 10, alphaLowFreq = 0)## Warning: The `guide` argument in `scale_*()` cannot be `FALSE`. This was deprecated in
## ggplot2 3.3.4.
## ℹ Please use "none" instead.
## ℹ The deprecated feature was likely used in the bartools package.
## Please report the issue to the authors.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.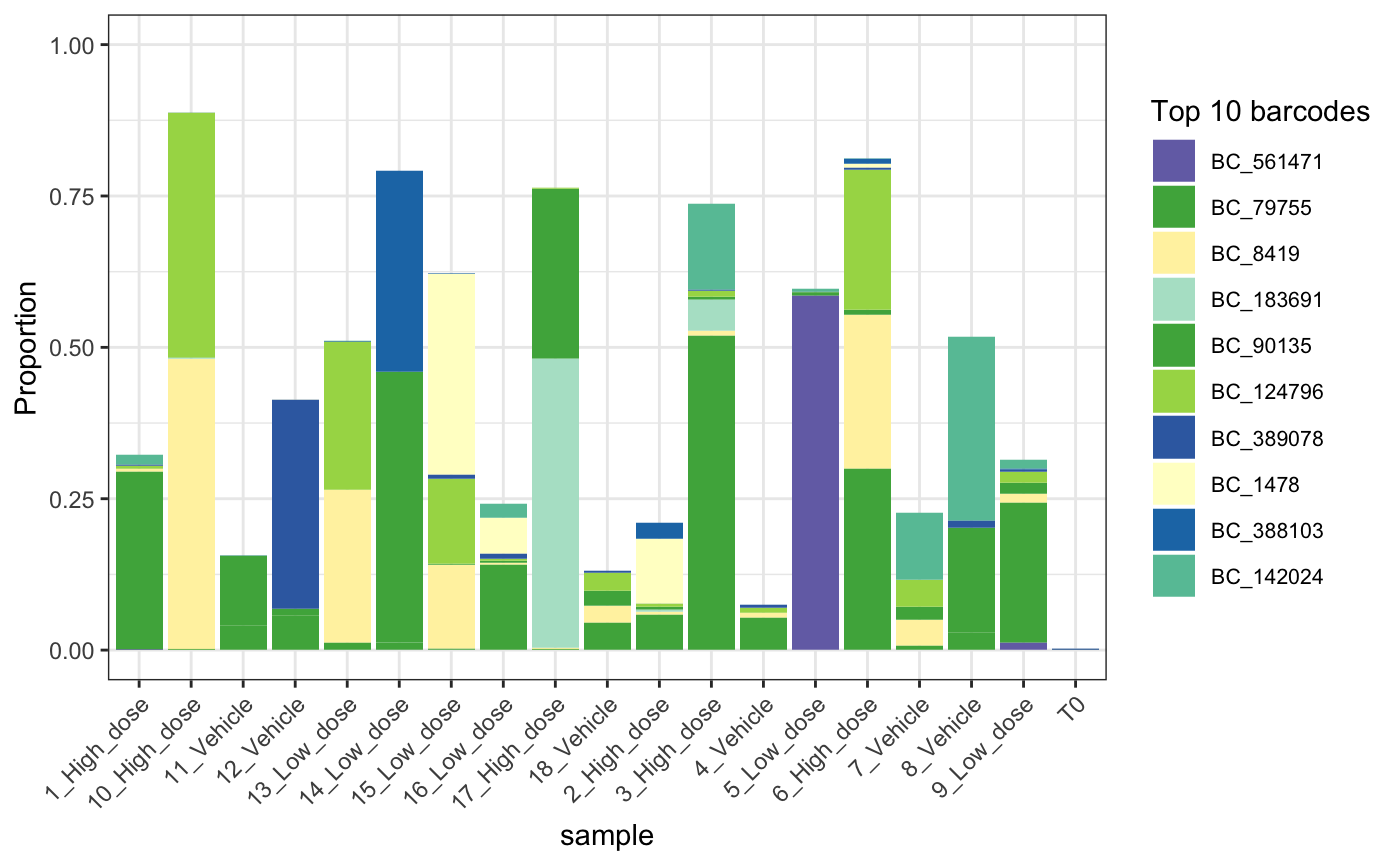
Timeseries Plots
For timecourse experiments it is useful to visualise how the kinetics
of barcode diversity changes over time. In this instance we can use
plotBarcodeTimeseries to get an idea of the relative
abundance of the top n barcodes in a sample relative to
others.
plotBarcodeTimeseries(dge.filtered.collapsed,
top = 50,
seed = 10101)## Using barcode as id variables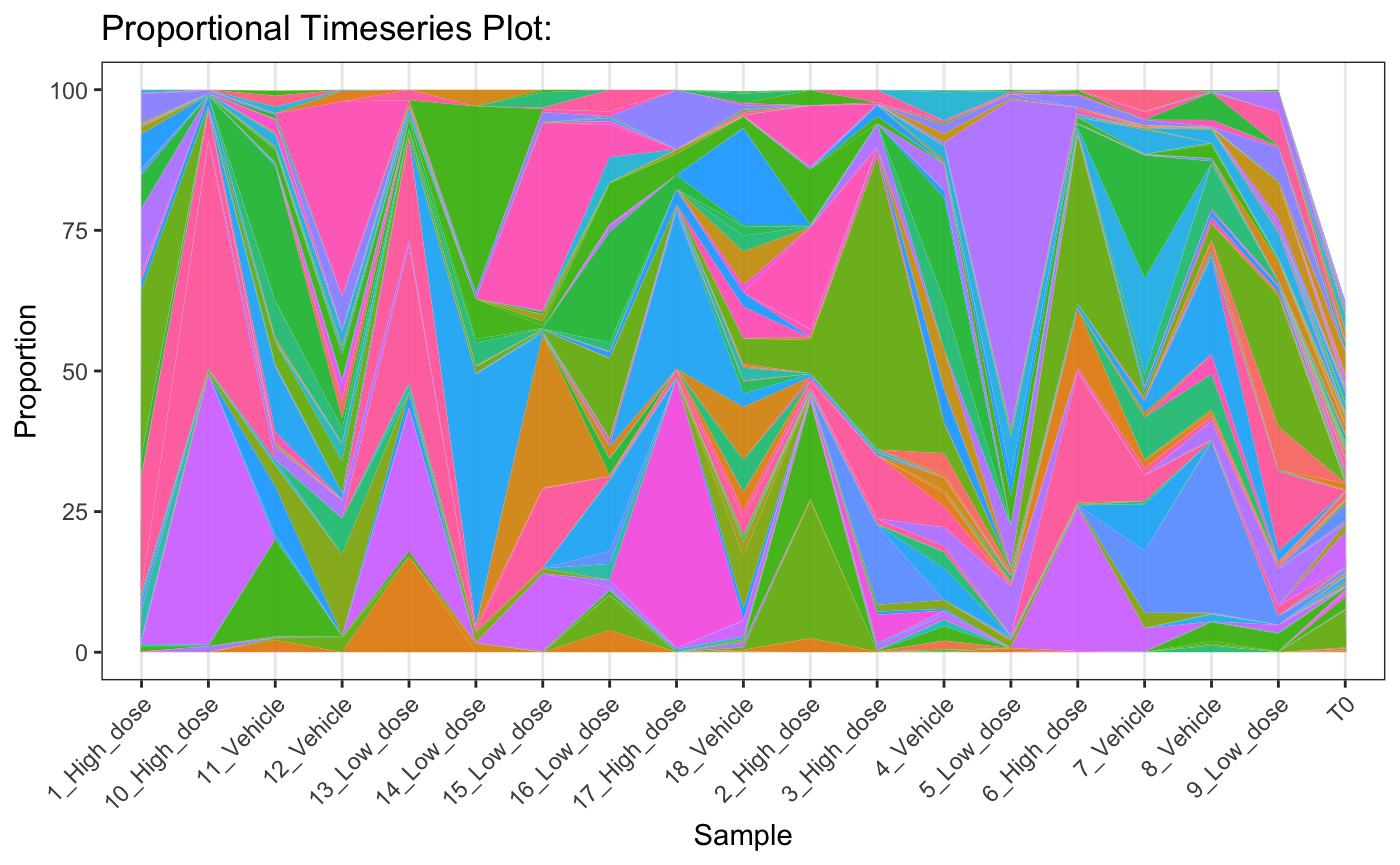
Principal Components Analysis
A global level PCA analysis is a good way to get a high level understanding of the similarities and differences between samples.
plotBarcodePCA(dge.filtered.collapsed,
groups = "Treatment",
ntop = 1000,
pcs=c(1, 2))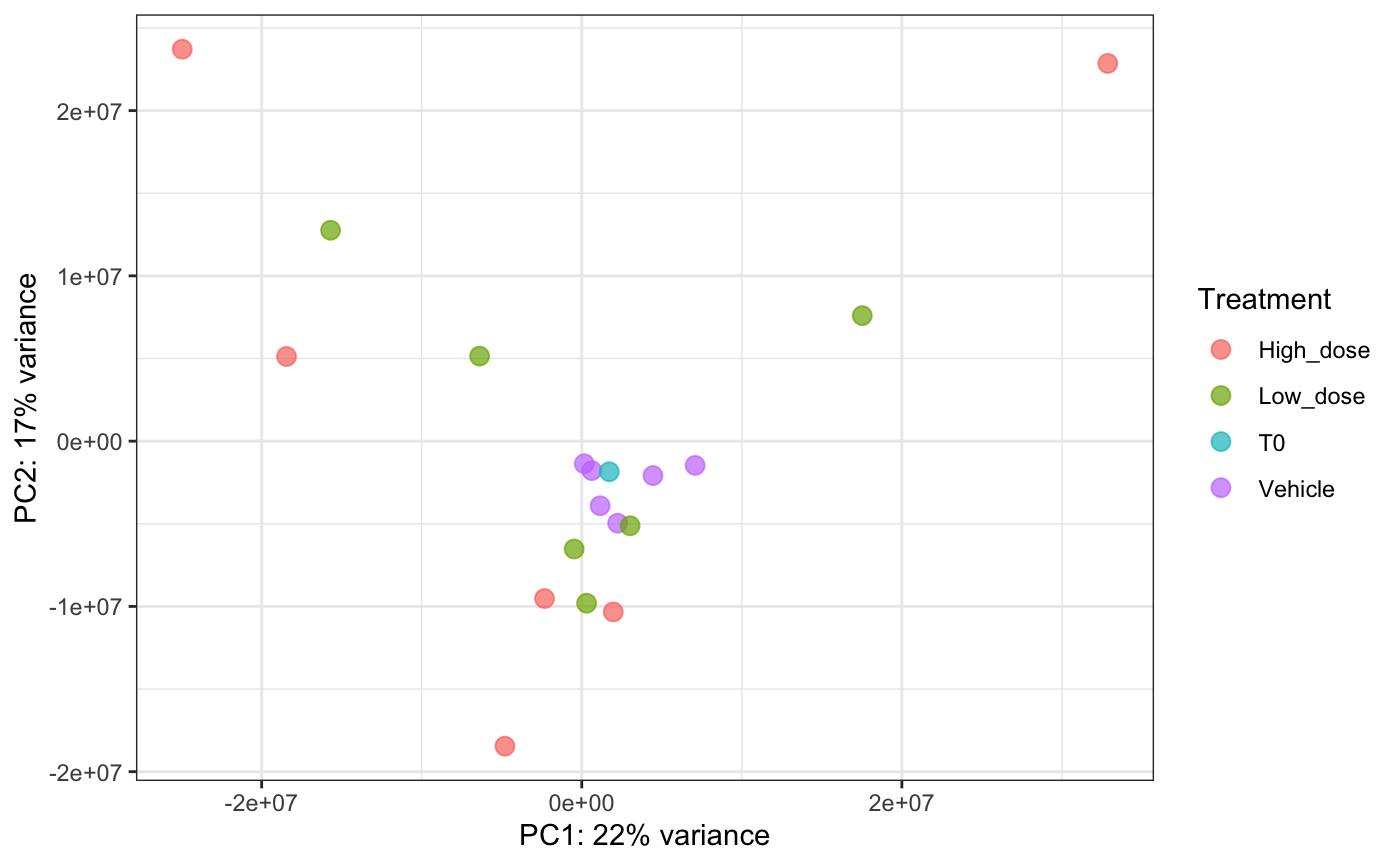
Heatmaps
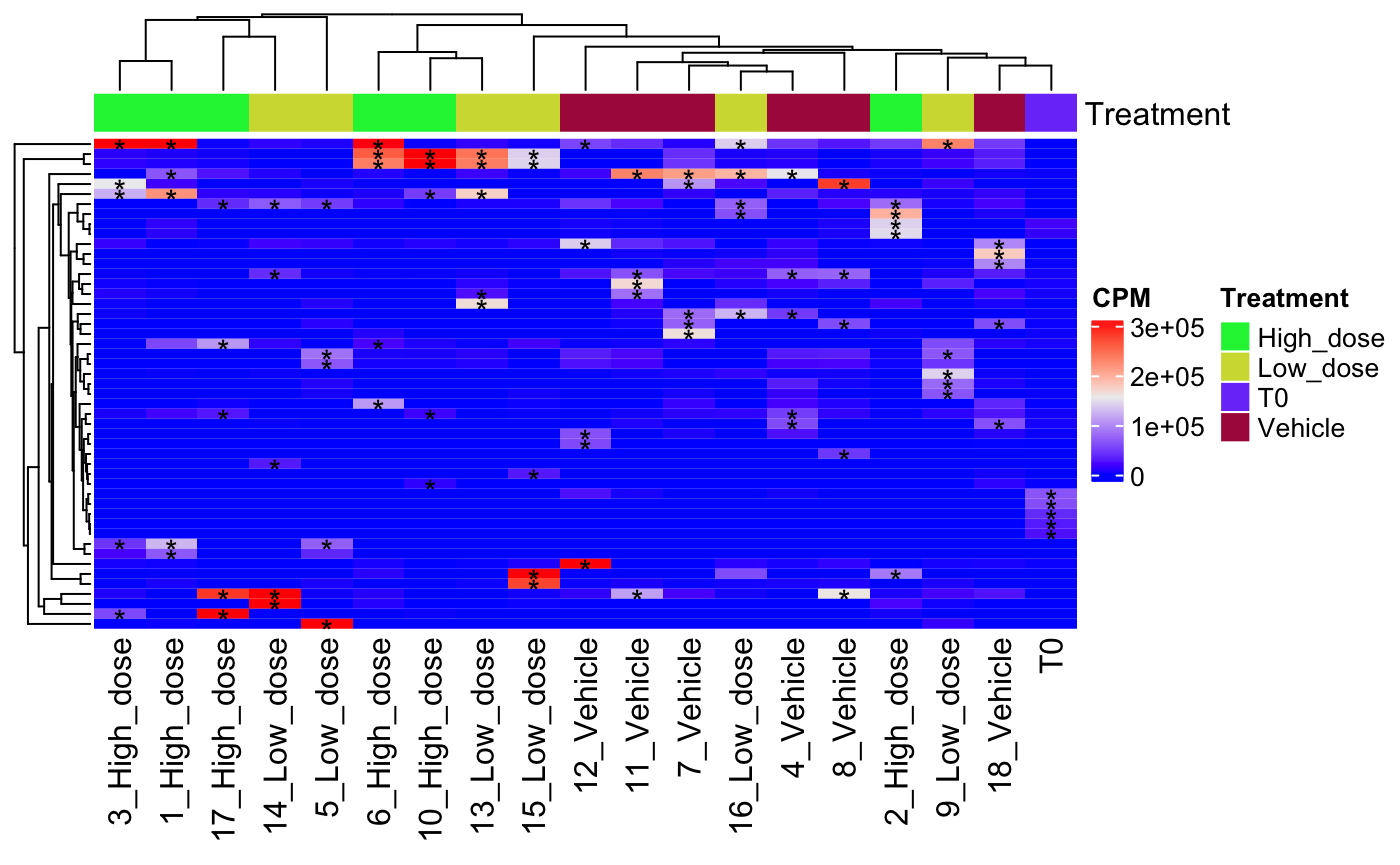
Another method of comparing abundance across samples is using a heatmap. Here barcodes ranked among the top n most abundant within each sample are indicated by an asterisk. This heatmap shows high dose samples are generally distinct from the low dose and vehicle group.
plotBarcodeHeatmap(
normaliseCounts(dge.filtered.collapsed, method = "CPM"),
topN = 5,
showBarcodes = F,
group = "Treatment"
)
4. Analysing Composition and Diversity
Its important to not only be able to visualise the data but also understand relationships between barcodes/tags at the data level.
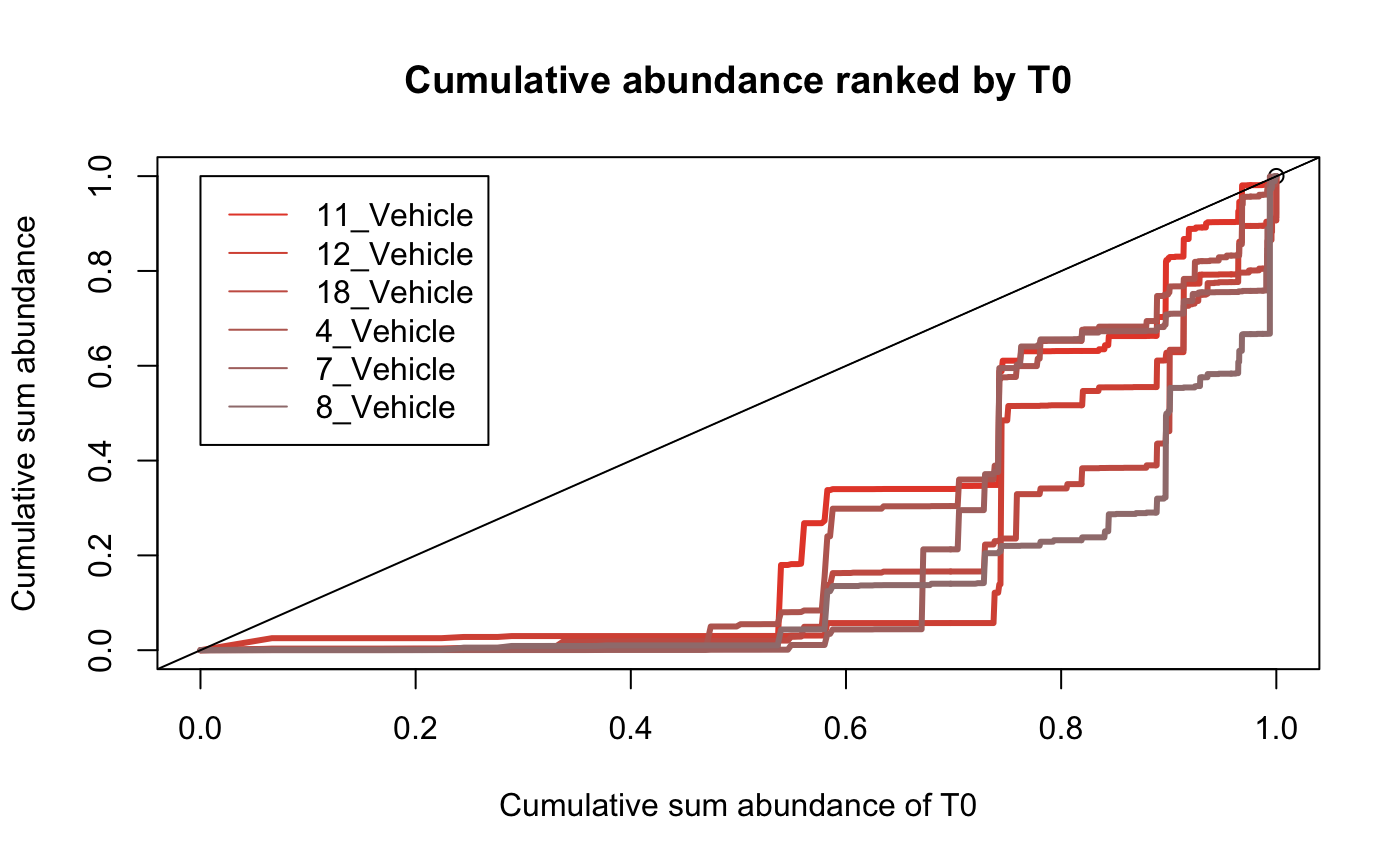
Identify compositional bias within samples
The above plots give a global visualisation of the abundance of each barcode within a sample however the compositional makeup can be obscured by visualising the data in this way. it can be helpful to examine the fraction of barcodes that comprise a sample. These plots calculate the cumulative sum of a sample in relation to other samples defined by the user.
samples <-
which(dge.filtered.collapsed$samples$Treatment == "Vehicle")
plotBarcodeCumSum(
dge.filtered.collapsed,
referenceSample = "T0",
samples = colnames(dge.filtered.collapsed$counts)[samples]
)
Identifying abundant barcodes within samples
It is important to be able to determine which barcodes are most
abundant within each sample. bartools allows this to be
easily calculated according to an abundance threshold.
top.bc <- getDominantBarcodes(dge.filtered.collapsed, threshold = 0.05)
top.bc[1:5]## $`1_High_dose`
## [1] "BC_79755" "BC_102160" "BC_59493" "BC_23361" "BC_53234" "BC_400391"
##
## $`10_High_dose`
## [1] "BC_8419" "BC_124796"
##
## $`11_Vehicle`
## [1] "BC_53234" "BC_205581" "BC_90135" "BC_172626" "BC_58978"
##
## $`12_Vehicle`
## [1] "BC_389078" "BC_159570" "BC_135438" "BC_500780" "BC_79755"
##
## $`13_Low_dose`
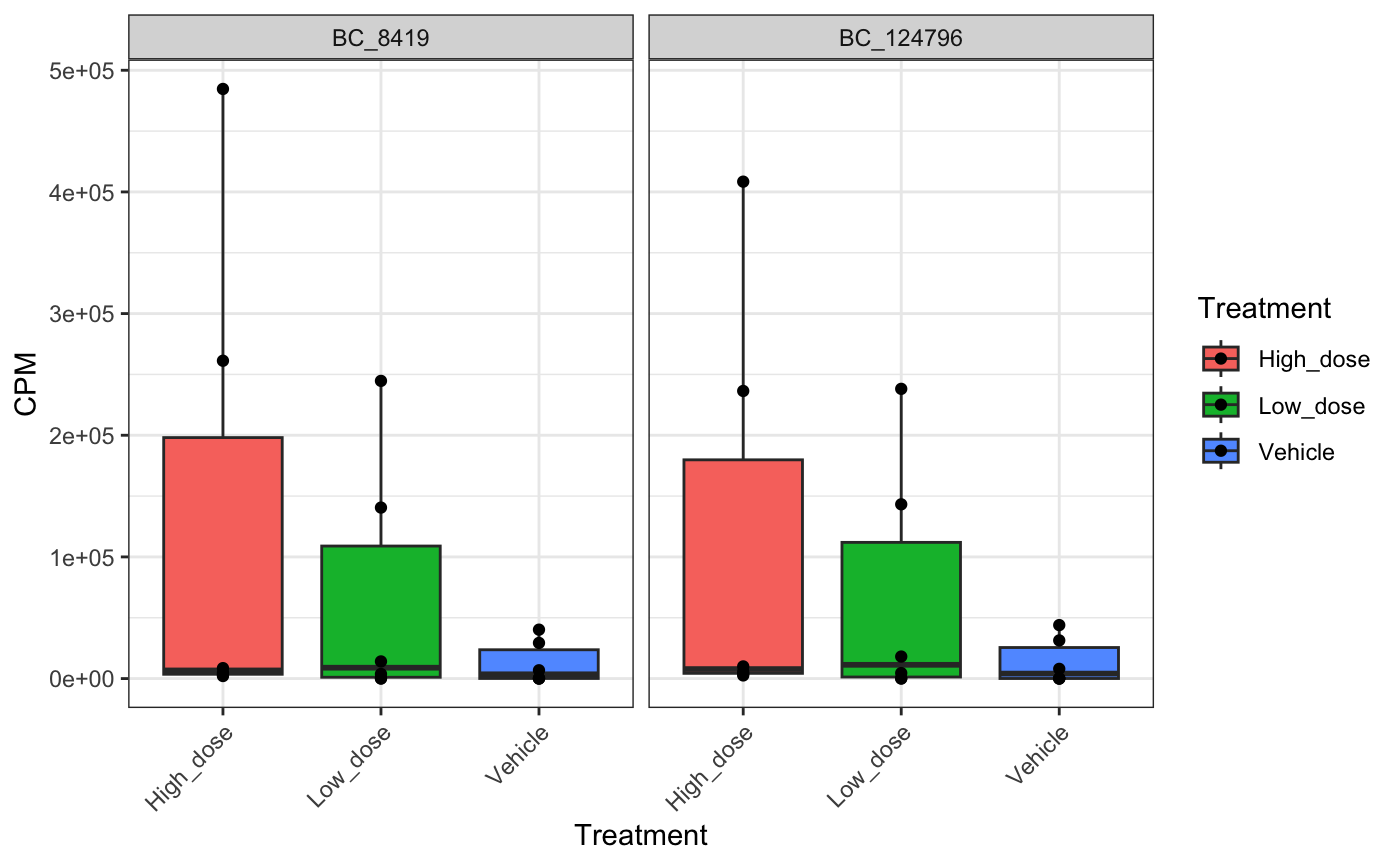
## [1] "BC_8419" "BC_124796" "BC_102160" "BC_257382"We can then use specific plots to visualise the dominance of specific barcodes within and across samples.
# plot top barcodes across samples for mouse 10 (High Dose group)
plotBarcodeBoxplot(
dge.filtered.collapsed,
barcodes = top.bc$`10_High_dose`,
group = "Treatment",
conditions = c("Low_dose", "High_dose", "Vehicle"),
point = T
)
Calculating and plotting percentile abundance.
The above graphs demonstrate that relatively few barcodes can sometimes comprise the majority of a sample’s clonality, particularly following a selective event such as drug treatment. It is useful to formally analyse this based on a desired percentile threshold. A common threshold is the 95th percentile. This can eliminate small barcodes that comprise the tail of the dataset and give a sense of how many clones truly comprise each sample
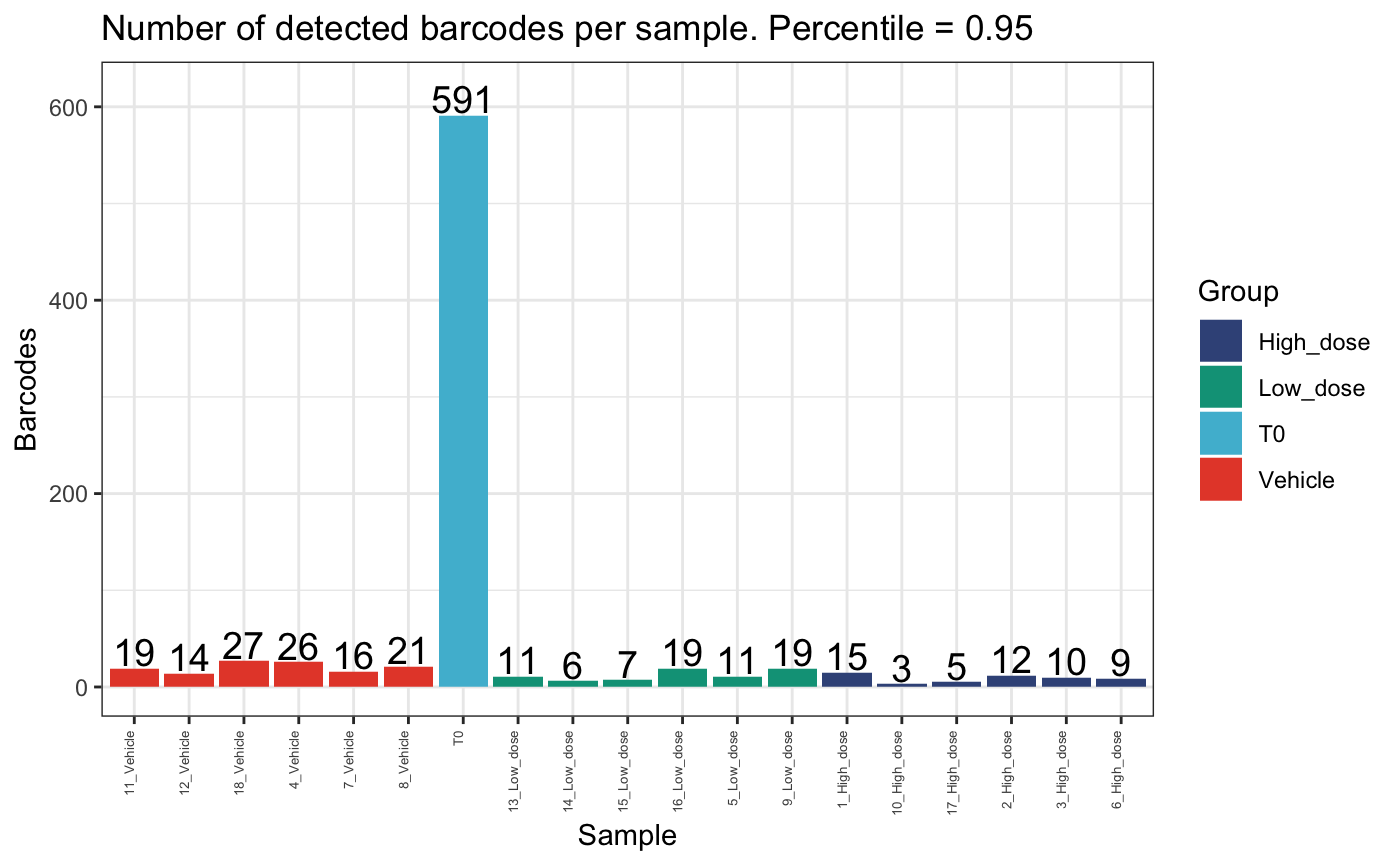
top_barcodes <- calcPercentileBarcodes(dge.filtered.collapsed, percentile = 0.95)
top_barcodes$NumBarcodes## Sample NumBarcodes
## 1 1_High_dose 15
## 2 10_High_dose 3
## 3 11_Vehicle 19
## 4 12_Vehicle 14
## 5 13_Low_dose 11
## 6 14_Low_dose 6
## 7 15_Low_dose 7
## 8 16_Low_dose 19
## 9 17_High_dose 5
## 10 18_Vehicle 27
## 11 2_High_dose 12
## 12 3_High_dose 10
## 13 4_Vehicle 26
## 14 5_Low_dose 11
## 15 6_High_dose 9
## 16 7_Vehicle 16
## 17 8_Vehicle 21
## 18 9_Low_dose 19
## 19 T0 591
top_barcodes$TopBarcodeCounts$`6_High_dose`## 6_High_dose
## BC_79755 1313507.0
## BC_8419 1120457.5
## BC_124796 1013931.0
## BC_4564 461928.0
## BC_400391 93601.5
## BC_31610 43251.5
## BC_1478 33933.5
## BC_90135 32480.0
## BC_388103 29467.0
top_barcodes$TopBarcodes$`6_High_dose`## [1] "BC_79755" "BC_8419" "BC_124796" "BC_4564" "BC_400391" "BC_31610"
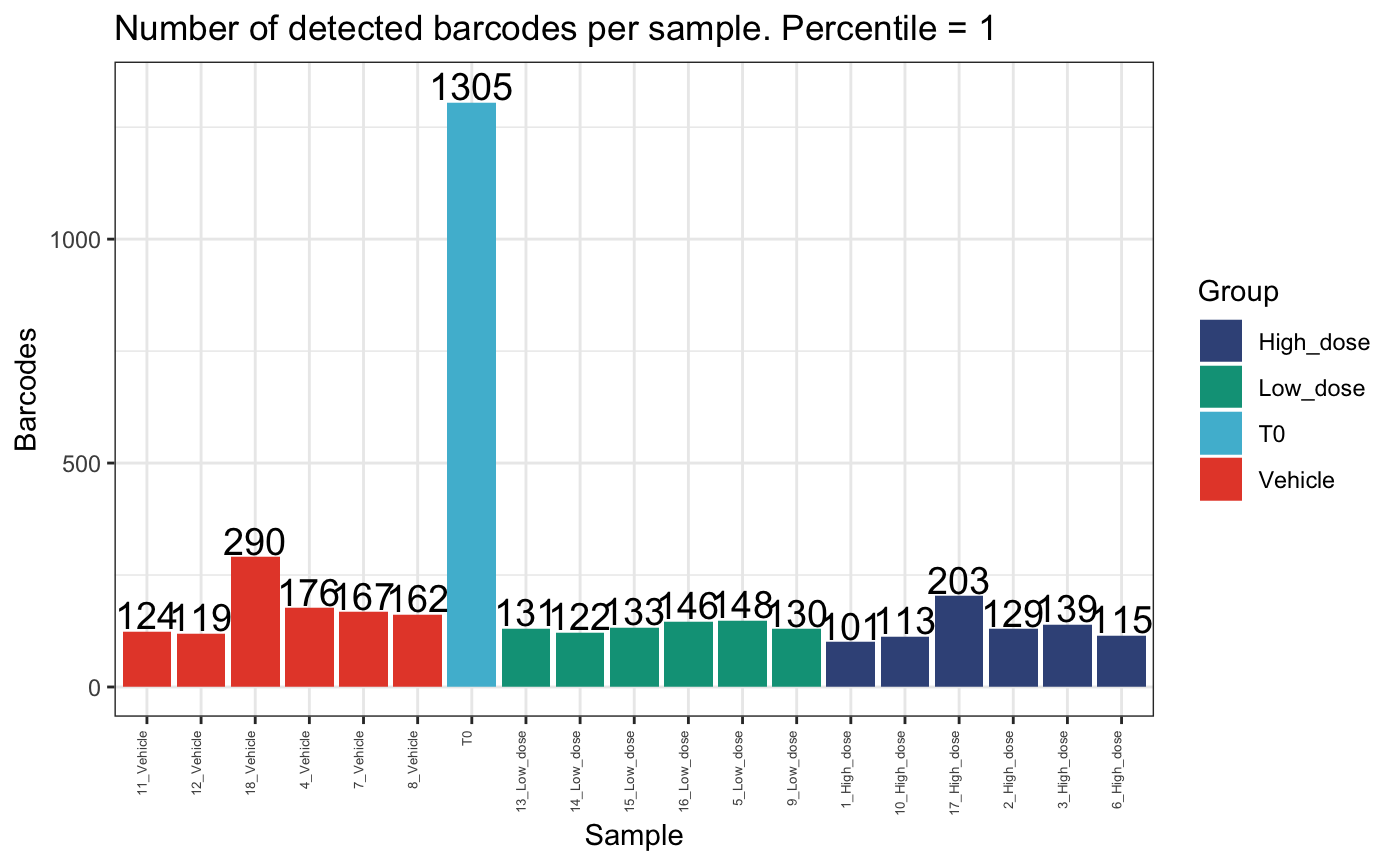
## [7] "BC_1478" "BC_90135" "BC_388103"We can compare the number of detected barcodes in the top 95th percentile per sample and the total sample.
plotDetectedBarcodes(
dge.filtered.collapsed,
percentile = 1,
plot = T,
group = "Treatment",
)
plotDetectedBarcodes(
dge.filtered.collapsed,
percentile = 0.95,
plot = T,
group = "Treatment"
)
plotDetectedBarcodes(
dge.filtered.collapsed,
percentile = 0.80,
plot = T,
group = "Treatment"
)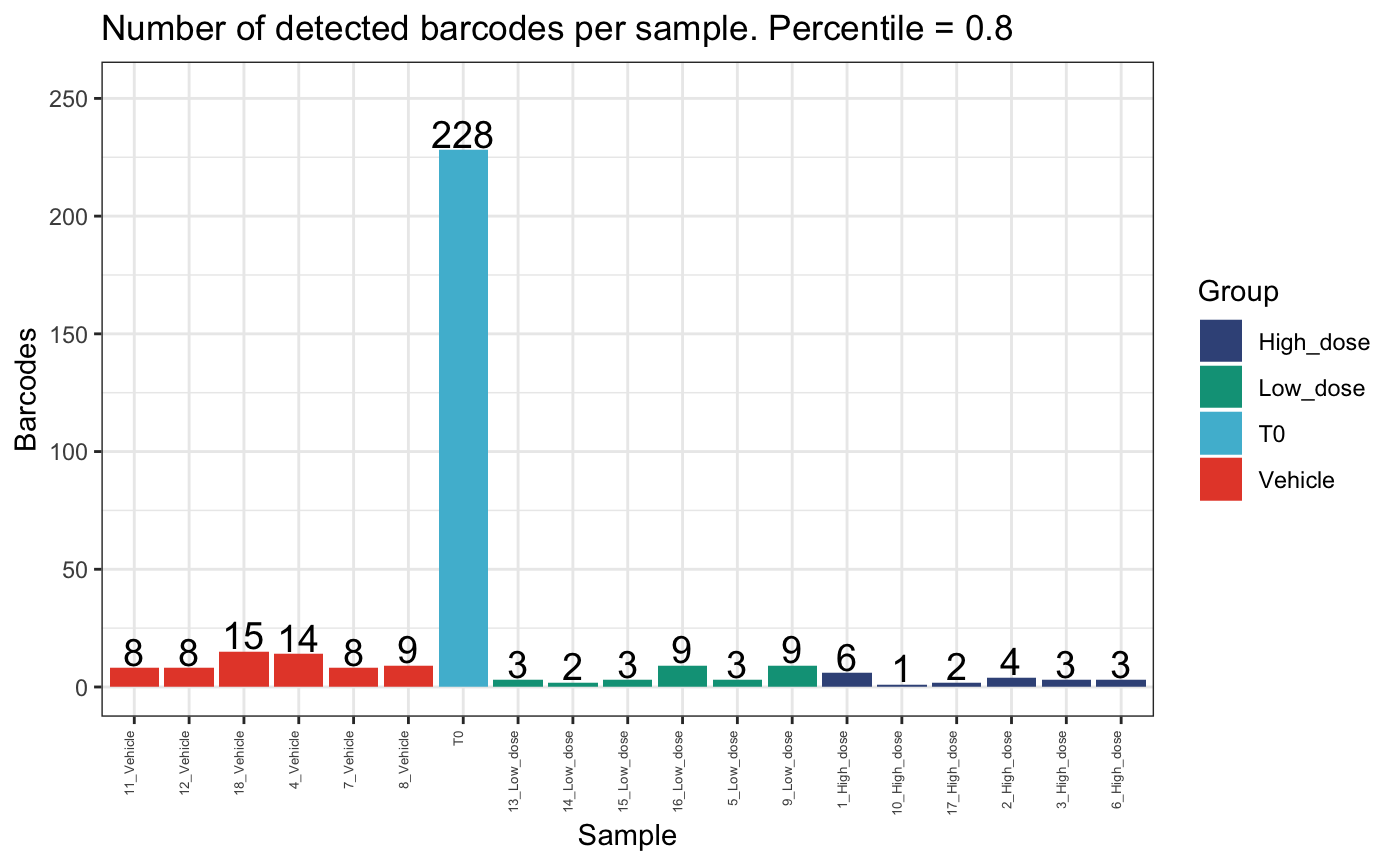
These plots show that there are few clones that comprise the majority of the dataset per mouse. Also, there are generally fewer clones present in the high dose group compared to the vehicle or low dose groups.
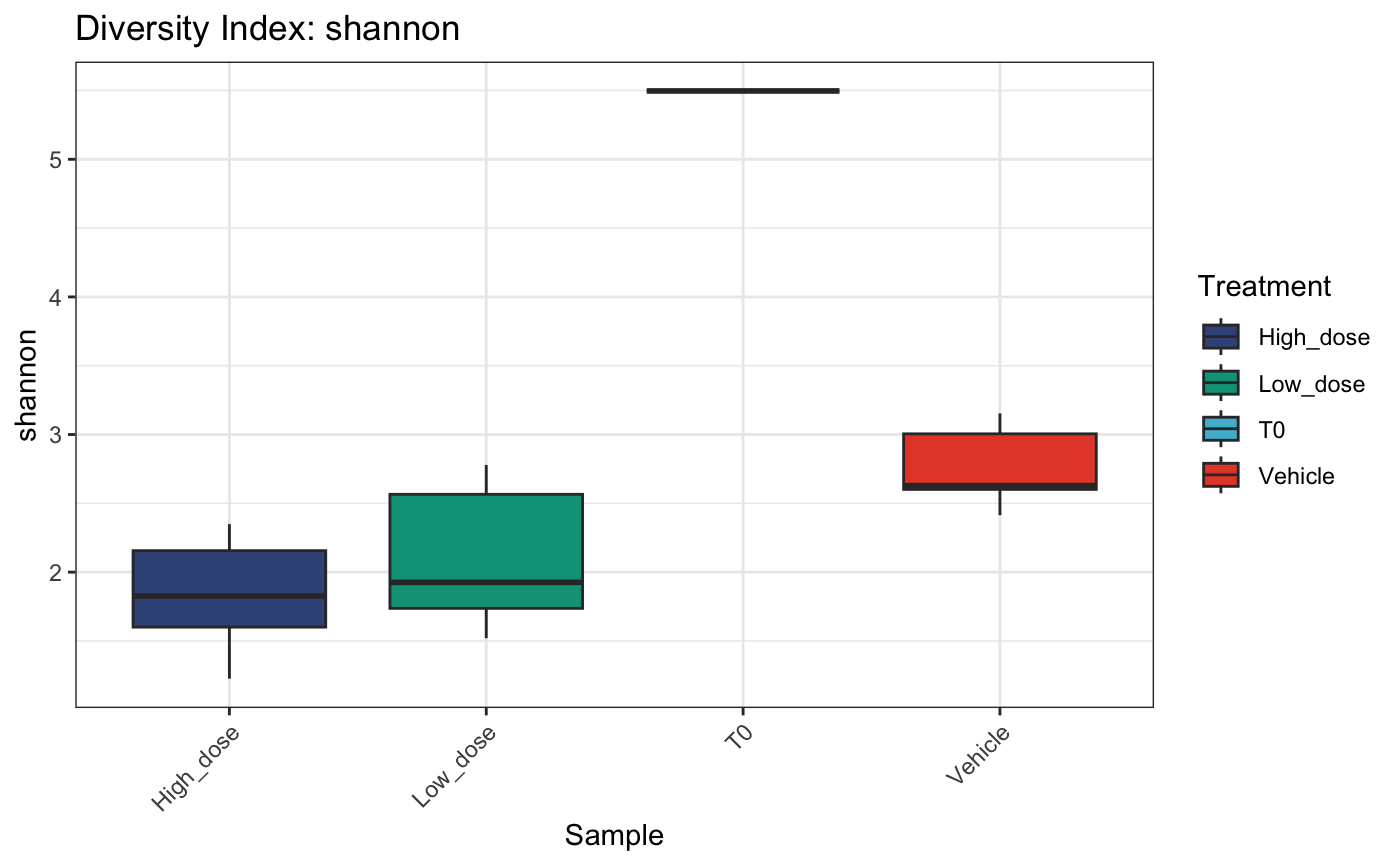
Diversity analysis
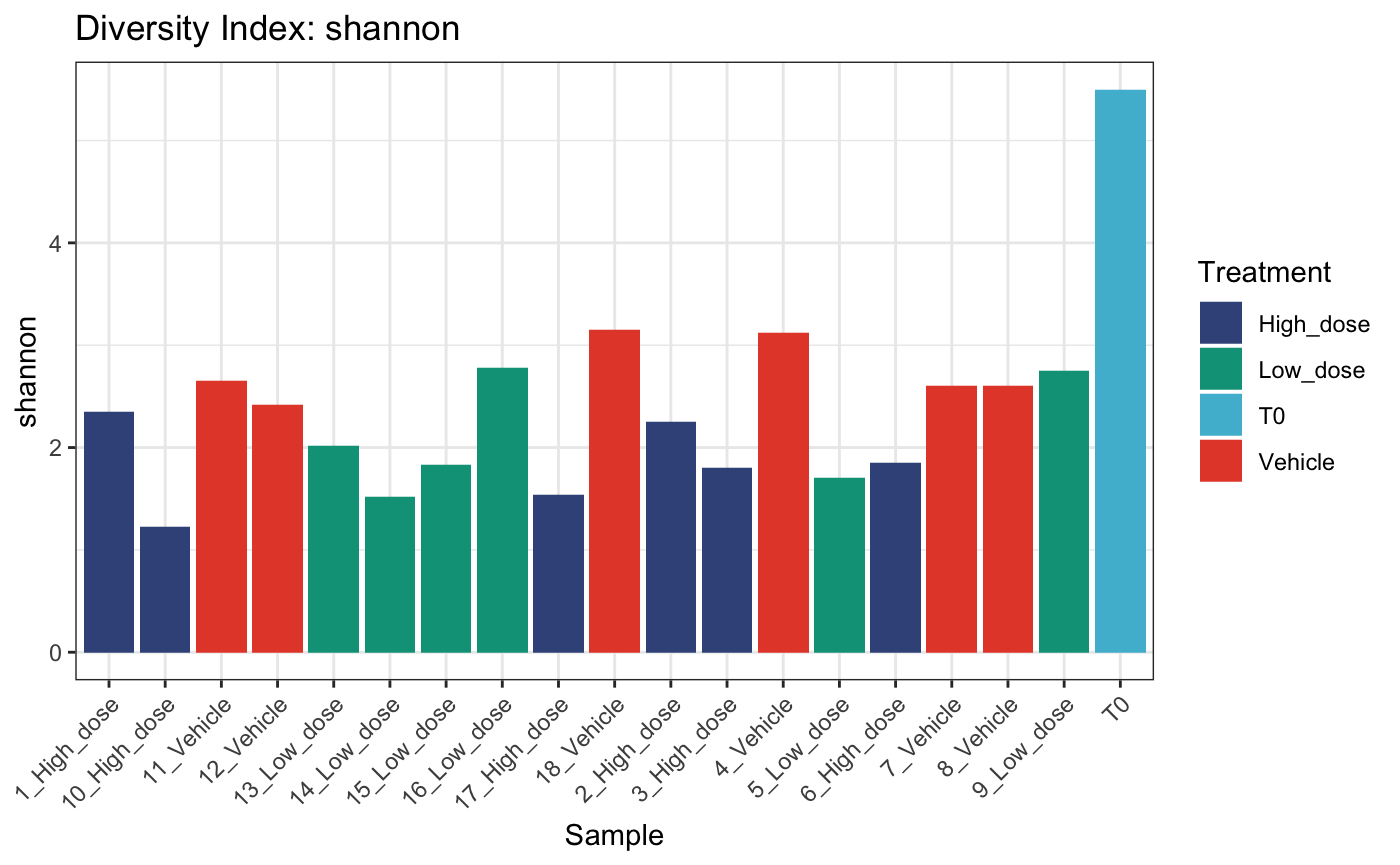
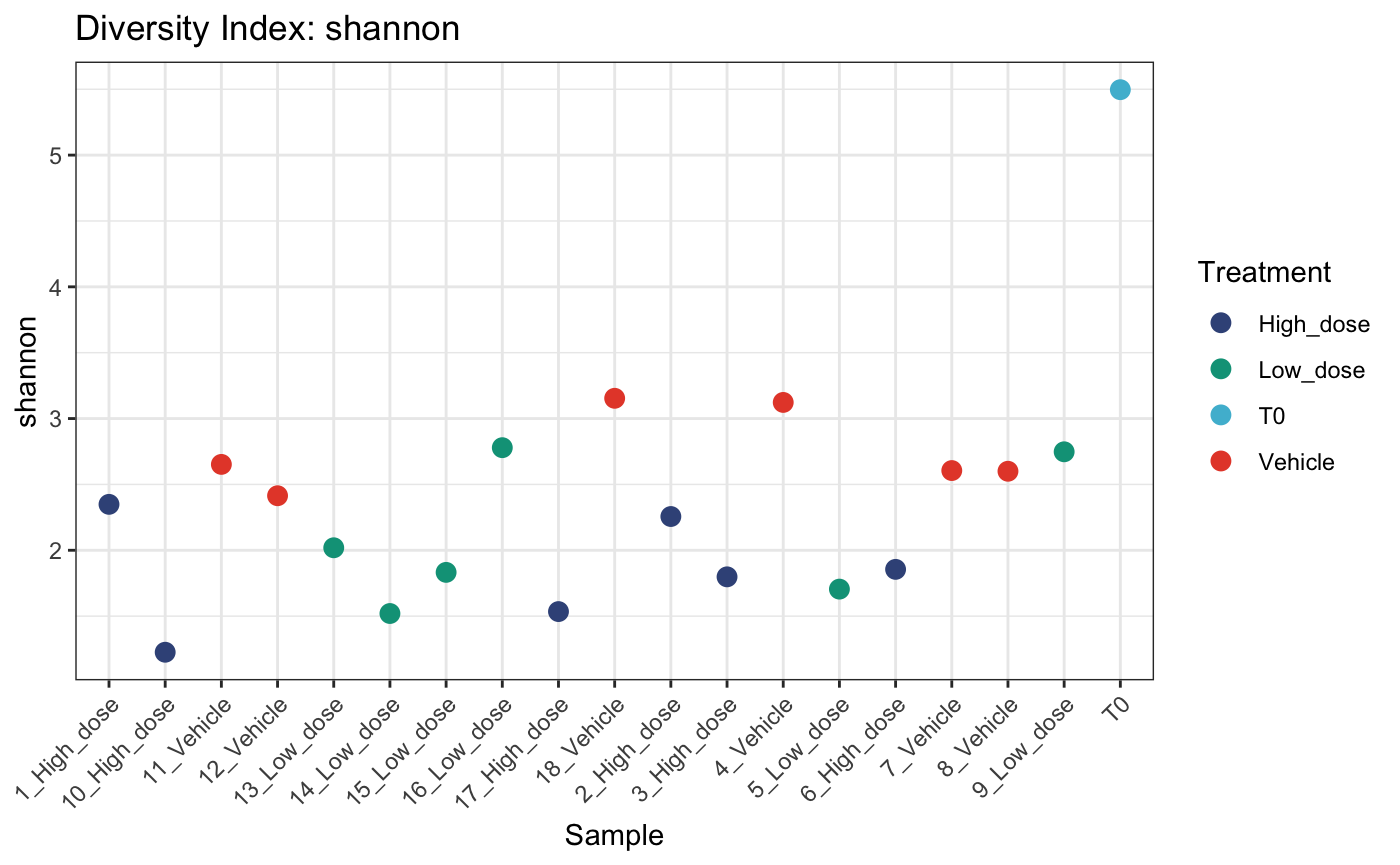
We can examine within-sample diversity in a few different ways. The most common are Shannon, Simpson, Inverse Simpson and Gini. Each will be applicable in different circumstances, however the Shannon diversity index is more widely used to compare global diversity amongst populations of barcoded cells.
calcDivIndexes can be used to determine various
diversity indices per sample
diversity <- calcDivIndexes(dge.filtered.collapsed, group = "Treatment")## Warning in xtfrm.data.frame(x): cannot xtfrm data frames
diversity## name shannon simpson invsimpson gini group
## 1 1_High_dose 2.348653 0.8444024 6.426835 0.9937718 <NA>
## 2 10_High_dose 1.225855 0.6032568 2.520522 0.9976422 <NA>
## 3 11_Vehicle 2.652009 0.8814286 8.433734 0.9914712 <NA>
## 4 12_Vehicle 2.414063 0.8399960 6.249843 0.9930451 <NA>
## 5 13_Low_dose 2.018988 0.8131654 5.352328 0.9952918 <NA>
## 6 14_Low_dose 1.519950 0.6814210 3.138939 0.9972041 <NA>
## 7 15_Low_dose 1.832241 0.7746745 4.438025 0.9961403 <NA>
## 8 16_Low_dose 2.778868 0.9048407 10.508698 0.9907836 <NA>
## 9 17_High_dose 1.534553 0.6789918 3.115185 0.9971341 <NA>
## 10 18_Vehicle 3.153789 0.9327042 14.859766 0.9864058 <NA>
## 11 2_High_dose 2.256249 0.8510421 6.713305 0.9943143 <NA>
## 12 3_High_dose 1.798299 0.6916723 3.243303 0.9959564 <NA>
## 13 4_Vehicle 3.122474 0.9318075 14.664379 0.9868916 <NA>
## 14 5_Low_dose 1.705062 0.6350995 2.740473 0.9959301 <NA>
## 15 6_High_dose 1.855066 0.7799154 4.543707 0.9958108 <NA>
## 16 7_Vehicle 2.605180 0.8891069 9.017692 0.9922683 <NA>
## 17 8_Vehicle 2.599855 0.8583819 7.061244 0.9915058 <NA>
## 18 9_Low_dose 2.747625 0.8980389 9.807663 0.9909330 <NA>
## 19 T0 5.496669 0.9850733 66.994135 0.7979588 <NA>These diversity calculations can then be fed to
plotDivIndexes for visualisation as either a bar or
dotplot
# bar plot
plotDivIndexes(
dge.filtered.collapsed,
div = diversity,
metric = "shannon",
group = "Treatment"
)
# dot plot
plotDivIndexes(
dge.filtered.collapsed,
div = diversity,
metric = "shannon",
group = "Treatment",
type = "point"
)
# summarized by condition as box plot
plotDivIndexes(
dge.filtered.collapsed,
div = diversity,
metric = "shannon",
group = "Treatment",
type = "box"
)
Comparing abundance
We can also statistically test for barcodes / tags that are over /
underrepresented in a group of samples relative to another using the
internal edgeR framework. bartools contains a convenience
wrapper for this functionality
compareAbundance(dge.filtered.collapsed,
group = "Treatment",
condition1 = "Low_dose",
condition2 = "High_dose",
pval = 1e-04,
logFC = 10)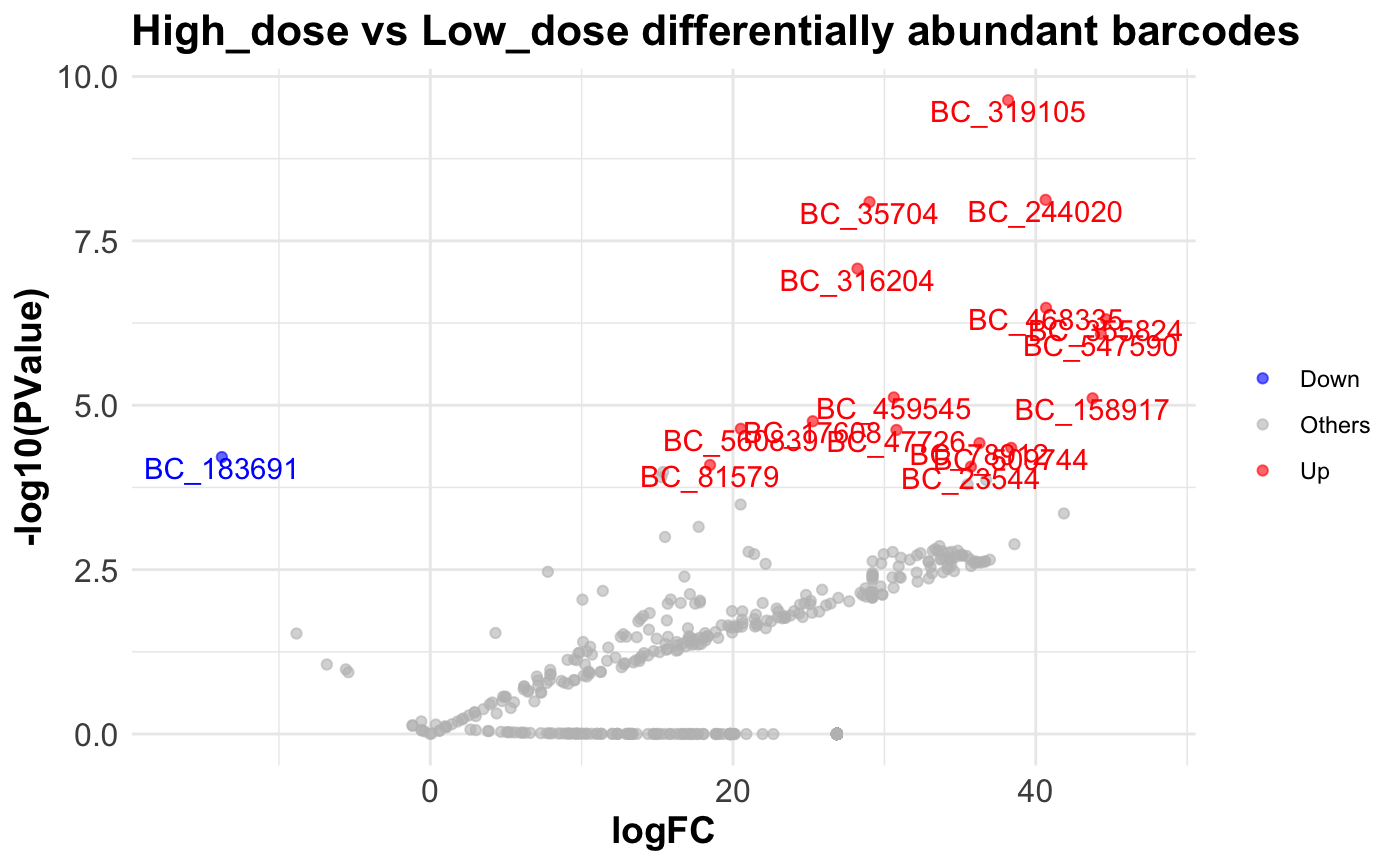
5. Session Info
## R version 4.2.2 (2022-10-31)
## Platform: aarch64-apple-darwin20 (64-bit)
## Running under: macOS 14.1.1
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] bartools_1.0.0 ggplot2_3.4.4 edgeR_3.40.2 limma_3.54.2
##
## loaded via a namespace (and not attached):
## [1] nlme_3.1-163 matrixStats_1.0.0 fs_1.6.3
## [4] doParallel_1.0.17 RColorBrewer_1.1-3 rprojroot_2.0.4
## [7] ggsci_3.0.0 tools_4.2.2 backports_1.4.1
## [10] bslib_0.6.0 utf8_1.2.4 R6_2.5.1
## [13] vegan_2.6-4 BiocGenerics_0.44.0 mgcv_1.9-0
## [16] colorspace_2.1-0 permute_0.9-7 GetoptLong_1.0.5
## [19] withr_2.5.2 tidyselect_1.2.0 compiler_4.2.2
## [22] textshaping_0.3.6 cli_3.6.1 Cairo_1.6-1
## [25] desc_1.4.2 labeling_0.4.3 sass_0.4.7
## [28] scales_1.2.1 pkgdown_2.0.7 systemfonts_1.0.5
## [31] stringr_1.5.1 digest_0.6.33 rmarkdown_2.25
## [34] pkgconfig_2.0.3 htmltools_0.5.7 fastmap_1.1.1
## [37] highr_0.10 rlang_1.1.2 GlobalOptions_0.1.2
## [40] rstudioapi_0.15.0 shape_1.4.6 jquerylib_0.1.4
## [43] farver_2.1.1 generics_0.1.3 jsonlite_1.8.7
## [46] dplyr_1.1.4 car_3.1-2 magrittr_2.0.3
## [49] Matrix_1.6-1.1 S4Vectors_0.36.2 Rcpp_1.0.11
## [52] munsell_0.5.0 fansi_1.0.5 abind_1.4-5
## [55] lifecycle_1.0.4 stringi_1.8.1 yaml_2.3.7
## [58] carData_3.0-5 MASS_7.3-60 plyr_1.8.9
## [61] grid_4.2.2 parallel_4.2.2 forcats_1.0.0
## [64] crayon_1.5.2 lattice_0.21-9 splines_4.2.2
## [67] circlize_0.4.15 magick_2.8.0 locfit_1.5-9.8
## [70] knitr_1.45 ComplexHeatmap_2.14.0 pillar_1.9.0
## [73] ggpubr_0.6.0 rjson_0.2.21 ggsignif_0.6.4
## [76] stats4_4.2.2 reshape2_1.4.4 codetools_0.2-19
## [79] glue_1.6.2 evaluate_0.23 vctrs_0.6.4
## [82] png_0.1-8 foreach_1.5.2 gtable_0.3.4
## [85] purrr_1.0.2 tidyr_1.3.0 clue_0.3-65
## [88] cachem_1.0.8 xfun_0.41 broom_1.0.5
## [91] rstatix_0.7.2 ragg_1.2.5 viridisLite_0.4.2
## [94] tibble_3.2.1 iterators_1.0.14 IRanges_2.32.0
## [97] ineq_0.2-13 memoise_2.0.1 cluster_2.1.4